| MCMD2 |
4.82 regexpos マッチ位置
書式1: regexpos(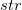 ,正規表現)
,正規表現)
書式2: regexposw(,正規表現)
指定した正規表現が最長マッチする文字列の部分文字列の開始位置を返す。 文字列の先頭位置は0であることに注意する。またマッチしなければNULL値を返す。 もしくは正規表現にマルチバイト文字を含む場合はregexposw関数を使うこと。
利用例
例1: 基本例
正規表現c.*aに最も長くマッチする部分文字列の位置を得る。 先頭文字の位置は0であることに注意する。 マッチした部分文字列についてはregexstrと同じ入力データを使っているので、比較すると分かりやすい。
$ more dat1.csv
id,str
1,xcbbbayy
2,xxcbaay
3,
4,bacabbca
$ mcal c='regexpos($s{str},"c.*a")' a=rsl i=dat1.csv o=rsl1.csv
#END# kgcal a=rsl c=regexpos($s{str},"c.*a") i=dat1.csv o=rsl1.csv
$ more rsl1.csv
id,str,rsl
1,xcbbbayy,1
2,xxcbaay,2
3,,
4,bacabbca,2
例2: マルチバイト文字
正規表現"い.*あ"に最も長くマッチする部分文字列の長さを得る。 ただし、以下ではマルチバイト文字対応でないregexpos関数を使っているので、 文字数ではなくバイト数でカウントした場合の位置を返している。
$ more dat2.csv
id,str
1,漢漢あbbbいyy
2,漢あbいいy
3,
4,bあいあbbいあ
$ mcal c='regexpos($s{str},"あ.*い")' a=rsl i=dat2.csv o=rsl2.csv
#END# kgcal a=rsl c=regexpos($s{str},"あ.*い") i=dat2.csv o=rsl2.csv
$ more rsl2.csv
id,str,rsl
1,漢漢あbbbいyy,6
2,漢あbいいy,3
3,,
4,bあいあbbいあ,1
例3: マルチバイト文字2
正規表現"い.*あ"に最も長くマッチする部分文字列の長さを得る。 regexposw関数を使うと、正しくマルチバイト文字を扱ってくれる。
$ mcal c='regexposw($s{str},"あ.*い")' a=rsl i=dat2.csv o=rsl3.csv
#END# kgcal a=rsl c=regexposw($s{str},"あ.*い") i=dat2.csv o=rsl3.csv
$ more rsl3.csv
id,str,rsl
1,漢漢あbbbいyy,2
2,漢あbいいy,1
3,,
4,bあいあbbいあ,1
| MCMD2 |