| MCMDRB |
| MCMDRB |
This class process CSV data file by row. The features are as follows.
Implemented in C++ and thus operate at high speed.
If the first row of data consists of field names, field names can be stored as key in hash data.
Hash / Array can be used for the storage of data (Array is 2 times faster).
Key break processing can be handled easily.
Loosely follow RFC 4180
Assumed that the number of items in each row is fixed.
* MCMD::Mcsvin::new(arguments){block}
Create Mcsvin object. Specify the list of arguments delimited by space in character string at “arguments” as follows.
i= |
Input file name (String) [required] |
k= |
Detect key break in the list of fields. Multiple fields are delimited by comma. |
Note the specification of key depends on yield arguments from each method. |
|
-nfn |
No field names in the first row. |
-array |
Store each data field by each method in Array. |
Data fields are stored in Hash by default if this is not specified. |
|
Storage in Array is 2 times more efficient than Hash (refer to benchmark for details). |
|
block |
Execute (yield) when block is specified. |
* MCMD::Mcsvin::each{|val| block}
* MCMD::Mcsvin::each{|val,top,bot| block}
Process CSV file one row at a time. 1) val is set to the value when key (k=) is not specified. 2) when key is specified, key break information is set in top and bot variables with the exception of val.
Set value in field name as key in Hash (or Array). Values are stored in string format.
Set to true if the start of key is specified at k=, otherwise, set to false. See remarks for more details.
Set to true if the end of key is specified at k=, otherwise, set to false. See remarks for more details.
* MCMD::Mcsvin::names()
Return field name array. Return nil if -nfn is specified.
Store data in Array if -nfn is specified. Note that data cannot be stored in Hash.
The specified field defined at k= must be sorted beforehand.
Logic of key break:
MCMD::Mcsvin.new("i=input.dat k=key"){|csv|
csv.each{|val,top,bot|
:
}
}
In the above code, the logic of top and bot settings in bool type block variable is as follows.
Data row 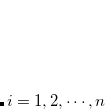 , value of key field ("key") in row
, value of key field ("key") in row  where
where  can simply be expressed as
can simply be expressed as 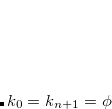 . Given
. Given 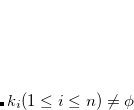 .
.
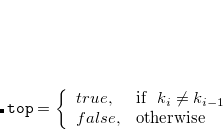 |
(2.1) |
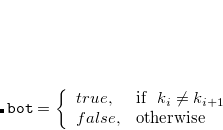 |
(2.2) |
# dat1.csv
customer,date,amount
A,20081201,10
B,20081002,40
MCMD::Mcsvin.new("i=dat1.csv"){|csv|
puts csv.names.join(",")
csv.each{|val|
p val
}
}
# Output results
customer,date,amount
["customer"=>"A", "date"=>"20081201", "amount"=>"10"]
["customer"=>"B", "date"=>"20081002", "amount"=>"40"]
# dat1.csv
customer,date
A,20081201
A,20081202
B,20081003
C,20081004
C,20081005
C,20081006
csv=MCMD::Mcsvin.new("i=dat1.csv k=customer")
csv.each{|val,top,bot|
puts "#{val['customer']},#{val['date']} top=#{top} bot=#{bot}"
}
csv.close
# Output results
A,20081201 top=true bot=false
A,20081202 top=false bot=true
B,20081003 top=true bot=true
C,20081004 top=true bot=false
C,20081005 top=false bot=false
C,20081006 top=false bot=true
Data is stored in Array when -nfn is specified.
# dat1.csv
A,20081201
A,20081202
MCMD::Mcsvin.new("i=dat1.csv k=1 -nfn"){|csv|
puts csv.names # -> nil
csv.each{|val|
p val
}
}
# Output results
nil
["A","20081201"]
["A","20081202"]
# dat1.csv
customer,date,amount
A,20081201,10
B,20081002,40
# Array storage with -array option
MCMD::Mcsvin.new("i=dat1.csv -array"){|csv|
puts csv.names.join(",")
csv.each{|val|
p val
}
}
# Output results
customer,date,amount
["A", "20081201", "10"]
["B", "20081002", "40"]
Mcsvout : Write to CSV data.
Mtable : Read data by cell from CSV file.
The processing speed for various Ruby extension library are benchmarked in terms of reading CSV data. The benchmark test targets the following 4 libraries and mcut command.
http://raa.ruby-lang.org/project/csvscan/
http://tmtm.org/ruby/lightcsv/
http://www.gesource.jp/programming/ruby/database/fastercsv.html
http://www.ruby-lang.org/ja/old-man/html/CSV.html
Fields are extracted with M-Command (implemented in C++). Speed performance is shown as reference.
The results of benchmark test is shown in Table 2.1. In this experiment, 10,000 to 500 million rows of data is read. The performance of Mscvin is almost equivalent to CSVScan (implemented in C). The difference is more significant for other libraries implemented in Ruby native code. However, Mcsvin lags behind when compared with mcut. The same parsing logic for CSV is used for mcut and Mcsvin, the difference due to the cost incurred when data is store in Array in Ruby interface. An excerpt of the script used in the benchmark test is shown in Figure 2.1.
Number of rows |
10K |
100K |
1000K |
2000K |
3000K |
4000K |
5000K |
Mcsvin |
0.020 |
0.196 |
1.76 |
3.51 |
5.26 |
7.02 |
8.79 |
CSVScan |
0.021 |
0.187 |
1.83 |
3.67 |
5.50 |
7.33 |
9.17 |
LightCsv |
0.155 |
1.62 |
15.99 |
– |
– |
– |
– |
FasterCSV |
0.196 |
1.96 |
19.50 |
– |
– |
– |
– |
CSV |
1.44 |
14.3 |
– |
– |
– |
– |
– |
mcut |
– |
– |
0.095 |
0.177 |
0.260 |
0.342 |
0.423 |
require 'rubygems'
require 'csv'
require 'fastercsv'
require 'lightcsv'
require 'csvscan'
require 'mcmd'
require 'benchmark'
puts Benchmark.measure{
(0...10).each{|i|
# Case of Mcsvin
csv=MCMD::Mcsvin.new("i=data.csv -array"){|csv| csv.each{|val|}}
# Case of CSVScan
File.open("data.csv","r"){|fp| CSVScan.scan(fp){|row|}}
# Case of LightCsv
LightCsv.foreach("data.csv"){|row|}
# Case of FasterCSV
FasterCSV.foreach("data.csv"){|row|}
# Case of CSV
CSV.open("data.csv", 'r'){|row|}
}
}
The next test looks at the difference in execution time corresponding to the types of data storage for data with or without key (Table 2.2). There is minimal difference in speed for data with or without key, however, the speed of data stored in Array is twice as fast as Hash.
Key |
Type |
1000K |
2000K |
3000K |
4000K |
5000K |
No |
Array |
1.76 |
3.51 |
5.26 |
7.02 |
8.79 |
No |
Hash |
3.52 |
6.99 |
10.50 |
14.00 |
17.52 |
Yes |
Array |
1.97 |
3.92 |
5.88 |
7.84 |
9.83 |
Yes |
Hash |
3.68 |
7.34 |
11.01 |
14.73 |
18.34 |
| MCMDRB |