| RubyM |
2.1 Mcsvin CSVの読み込みクラス
CSVデータファイルを行単位で処理するためのクラス。以下のような特徴を持つ。
C++で実装されており高速に動作する。
一行目が項目名行であれば、項目名をkeyとするHashにデータを格納できる。
データの格納はHash/Arrayを選択可能(Arrayの方が2倍高速)。
キーブレイク処理を容易に扱える。
RFC4180にほぼ準拠
一行の項目数は固定であることを前提とする。
2.1.1 メソッド
* MCMD::Mcsvin::new(arguments){block}
Mcsvinオブジェクトを生成する。 argumentsに、以下の引数をスペースで区切った文字列として指定する。
i= |
入力ファイル名(String) 【必須】 |
k= |
キーブレイクを検知する項目リスト。複数項目はカンマで区切る。 |
キー指定の有無によってeachメソッドのyield引数が異なることに注意する。 |
|
-nfn |
1行目を項目名と見なさない。 |
-array |
eachメソッドで各データ項目をArrayに格納する。 |
指定がなければHashに格納する。 |
|
ArrayはHashに比べ、約2倍効率的である(詳細は「ベンチマーク」を参照)。 |
|
block |
ブロックがが指定されていれば実行(yield)する。 |
* MCMD::Mcsvin::each{|val| block}
* MCMD::Mcsvin::each{|val,top,bot| block}
CSVファイルを一行ずつ処理する。 1)の書式はキー(k=)を指定しなかった場合で、valに値が設定される。 2)の書式はキーを指定した場合で、val以外にもキーブレイク情報top,botの変数も設定される。
- val
項目名をキーとして値を格納したHash(もしくはArray)。値は全てString型で格納。
- top
k=で指定したキーの先頭であればtrue、さもなければfalseがセットされる。詳細は備考を参照。
- bot
k=で指定したキーの終端であればtrue、さもなければfalseがセットされる。詳細は備考を参照。
* MCMD::Mcsvin::names()
項目名配列を返す。-nfnが指定されていればnilを返す。
2.1.2 備考
-nfnが指定された場合、データはArrayに格納される。Hashでは格納できない。
k=を指定する場合は、そこで指定した項目で並べ替えておかなければならない。
キーブレイクのロジック:
MCMD::Mcsvin.new("i=input.dat k=key"){|csv| csv.each{|val,top,bot| : } }上記のコードにおいて、bool型のブロック変数topおよびbotの設定ロジックは以下のとおり。
データ行を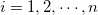 、
、 行目のキー項目(“key”)の値を
行目のキー項目(“key”)の値を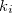 とし、便宜上
とし、便宜上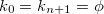 とする。ただし、
とする。ただし、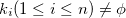 である。
である。 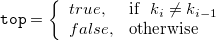
(2.1) 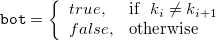
(2.2)
2.1.3 利用例
例1 項目名の出力と行番号・値の出力
# dat1.csv
顧客,日付,金額
A,20081201,10
B,20081002,40
MCMD::Mcsvin.new("i=dat1.csv"){|csv|
puts csv.names.join(",")
csv.each{|val|
p val
}
}
# 出力結果
顧客,日付,金額
["顧客"=>"A", "日付"=>"20081201", "金額"=>"10"]
["顧客"=>"B", "日付"=>"20081002", "金額"=>"40"]
例2 キーブレイク処理
# dat1.csv
顧客,日付
A,20081201
A,20081202
B,20081003
C,20081004
C,20081005
C,20081006
csv=MCMD::Mcsvin.new("i=dat1.csv k=顧客")
csv.each{|val,top,bot|
puts "#{val['顧客']},#{val['日付']} top=#{top} bot=#{bot}"
}
csv.close
# 出力結果
A,20081201 top=true bot=false
A,20081202 top=false bot=true
B,20081003 top=true bot=true
C,20081004 top=true bot=false
C,20081005 top=false bot=false
C,20081006 top=false bot=true
例3 項目名行のないデータの処理
-nfnを指定するとArrayに格納される。
# dat1.csv
A,20081201
A,20081202
MCMD::Mcsvin.new("i=dat1.csv k=1 -nfn"){|csv|
puts csv.names # -> nil
csv.each{|val|
p val
}
}
# 出力結果
nil
["A","20081201"]
["A","20081202"]
例4 Arrayに格納する例
# dat1.csv
顧客,日付,金額
A,20081201,10
B,20081002,40
# -arrayオプションでArray格納
MCMD::Mcsvin.new("i=dat1.csv -array"){|csv|
puts csv.names.join(",")
csv.each{|val|
p val
}
}
# 出力結果
顧客,日付,金額
["A", "20081201", "10"]
["B", "20081002", "40"]
関連コマンド
Mcsvout : CSVデータの書き込み
Mtable : セル単位読み込み操作
2.1.4 ベンチマークテスト
CSVデータの読み込み処理について、Rubyの拡張ライブラリとして提供されている 各種ライブラリをベンチマークとして処理速度の比較を行う。 ベンチマーク対象は以下の4つのライブラリと1つのコマンドである。
- CSVScan
http://raa.ruby-lang.org/project/csvscan/
- LightCsv
http://tmtm.org/ruby/lightcsv/
- FasterCSV
http://www.gesource.jp/programming/ruby/database/fastercsv.html
- CSV
http://www.ruby-lang.org/ja/old-man/html/CSV.html
- mcut
項目を切り出すMコマンド(全てC++で実装)。参考までに掲載。
Table 2.1にベンチマークテストの結果を示す。 1万行〜500万行のデータについて読み込み実験を行った。 Figure 2.1には、ベンチマークテストで利用したスクリプトの抜粋が示されている。 McsvinはCSVScan(Cによる実装)とほぼ同等性能である。 その他はいずれもRubyネイティブコードによる実装なのでその差があらわれていることがわかる。 ただし、mcutとの比較においては、Mcsvinも到底及ばない。 mcutとMcsvinで採用しているCSVのparsingロジックおよびその実装は全く同じであるので、 データをArrayに格納するなどのRubyとのインターフェースにまつわるコストによって、 ここまでの差が出ていることになる。Figure 2.1に、ベンチマークテストで利用したスクリプトの抜粋を示す。
行数 |
10K |
100K |
1000K |
2000K |
3000K |
4000K |
5000K |
Mcsvin |
0.020 |
0.196 |
1.76 |
3.51 |
5.26 |
7.02 |
8.79 |
CSVScan |
0.021 |
0.187 |
1.83 |
3.67 |
5.50 |
7.33 |
9.17 |
LightCsv |
0.155 |
1.62 |
15.99 |
– |
– |
– |
– |
FasterCSV |
0.196 |
1.96 |
19.50 |
– |
– |
– |
– |
CSV |
1.44 |
14.3 |
– |
– |
– |
– |
– |
mcut |
– |
– |
0.095 |
0.177 |
0.260 |
0.342 |
0.423 |
10回実行した結果の平均値(real time)を示している。
– は値が大き(小さ)過ぎるために計測していないことを意味する。
行数10Kは10000行の意味。データのサイズは行数が1000Kで約25Mバイト。項目数は5つ。
バージョン: CSVScan 0.0.20070920, FasterCSV 1.5.1, LightCsv 0.2.2 CSV(Ruby 1.8.7)
テスト環境: Mac Book Pro, 2.66GHz Intel Core i7, 8GB メモリ, Mac OS X 10.6.8
require 'rubygems'
require 'csv'
require 'fastercsv'
require 'lightcsv'
require 'csvscan'
require 'mcmd'
require 'benchmark'
puts Benchmark.measure{
(0...10).each{|i|
# Mcsvinの場合
csv=MCMD::Mcsvin.new("i=data.csv -array"){|csv| csv.each{|val|}}
# CSVScanの場合
File.open("data.csv","r"){|fp| CSVScan.scan(fp){|row|}}
# LightCsvの場合
LightCsv.foreach("data.csv"){|row|}
# FasterCSVの場合
FasterCSV.foreach("data.csv"){|row|}
# CSVの場合
CSV.open("data.csv", 'r'){|row|}
}
}
次に、Mcsvinにおいて、キー指定の有無およびデータを格納する型による実行時間の差について見てみる(Table 2.2)。 キー指定の有無による速度には、さほど大きな違いはないが、データの格納型については、 ArrayがHashより2倍ほど効率的である。
キー |
型 |
1000K |
2000K |
3000K |
4000K |
5000K |
なし |
Array |
1.76 |
3.51 |
5.26 |
7.02 |
8.79 |
なし |
Hash |
3.52 |
6.99 |
10.50 |
14.00 |
17.52 |
あり |
Array |
1.97 |
3.92 |
5.88 |
7.84 |
9.83 |
あり |
Hash |
3.68 |
7.34 |
11.01 |
14.73 |
18.34 |
キーのサイズは平均10行程度。
| RubyM |