| MCMD2 |
| MCMD2 |
A natural join selects rows from input data and reference file that have equal values in columns defined at k= parameter, the reference file is specified at the m= parameter, fields in the reference file specified at f= parameter is added through natural join. The difference with mjoin command is that key field(s) in the reference field is not unique.
Given that the input data has 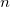 records with a certain key value, and the reference file has
records with a certain key value, and the reference file has 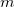 records with the same key value,
records with the same key value,  records will be generated. In addition, if f= is not defined, all fields except the key field will be added.
records will be generated. In addition, if f= is not defined, all fields except the key field will be added.
mnjoin k= [f=] [K=] [-n] [-N] m=| i= [o=] [bufcount=] [-nfn] [-nfno] [-x] [-q] [--help] [--version]
k= key field name(s) from the input data for matching This key field is specified in the input data and at the K= parameter. Join rows when this fields matches with the fields from the reference data. f= Specify the field name(s) to join from the reference file. When this parameter is not defined, all fields except the key field will be joined. m= Reference file name. Read from standard input if this parameter is not set. (when i= is specified) K= Key field name(s) from the reference data for matching This key field(s) from reference data is compared with the key field(s) from input data specified at k= parameter, fields where records with common key are joined. This parameter is not required if the field name in reference file is the same as the one defined at the k=parameter. -n Output NULL values when reference data does not consist of input data. -N Output NULL values when input data does not consist of reference data.
The item field in the input file is compared with the item field from the reference file, add cost field for records with the same value. There are two records where item=A in both input file and reference file, therefore, 2 2=4 rows of item=A is written to the output file.
2=4 rows of item=A is written to the output file.
$ more dat1.csv item,date,price A,20081201,100 A,20081213,98 B,20081002,400 B,20081209,450 C,20081201,100 $ more ref1.csv item,cost A,50 A,70 B,300 E,200 $ mnjoin k=item f=cost m=ref1.csv i=dat1.csv o=rsl1.csv #END# kgnjoin f=cost i=dat1.csv k=item m=ref1.csv o=rsl1.csv $ more rsl1.csv item%0,date,price,cost A,20081201,100,50 A,20081201,100,70 A,20081213,98,50 A,20081213,98,70 B,20081002,400,300 B,20081209,450,300
Use -n to print records in the input data that do not match with those in the reference file (row where item="C"), and use -N to print records in the reference file that do not match with those in the input file (row where item="E").
$ more ref2.csv item,cost A,50 B,300 E,200 $ mnjoin k=item f=cost m=ref2.csv -n -N i=dat1.csv o=rsl2.csv #END# kgnjoin -N -n f=cost i=dat1.csv k=item m=ref2.csv o=rsl2.csv $ more rsl2.csv item%0,date,price,cost A,20081201,100,50 A,20081213,98,50 B,20081002,400,300 B,20081209,450,300 C,20081201,100, E,,,200
mjoin : It is faster to use mjoin if the key in the reference file is unique.
mproduct : Join combination of all records without using key. Each row in the reference file is joined with all records in the input data.
| MCMD2 |