| MCMD2 |
| MCMD2 |
Specify the field at the f= parameter, and specify the normalization method at c= parameter.
mnormalize c= f= [k=] [i=] [o=] [bufcount=] [-nfn] [-nfno] [-x] [-q] [precision=] [--help] [--version]
c= Specify the normalisation method listed as follows. z : z score : Z : deviation value : range : use linear conversion to transform minimum value 0 to maximum value 1 f= Specify the field to normalize here. Specify the new field name after :(colon). Example: f=quantity:quantityNorm k= Key field name(s) [aggregate key break processing] The key field specified is used as the unit for normalization.
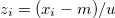 (
(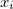 :
:  number of data,
number of data, 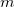 :arithmetic mean,
:arithmetic mean,  :standard deviation)
:standard deviation)
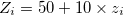
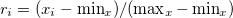
Normalize (z score) quantity and amount field based on each customer, label the column names of the output as qtyNominal and amtNorminal respectively.
$ more dat1.csv customer,quantity,amount A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ mnormalize c=z k=customer f=quantity:qtyNominal,amount:amtNorminal i=dat1.csv o=rsl1.csv #END# kgnormalize c=z f=quantity:qtyNominal,amount:amtNorminal i=dat1.csv k=customer o=rsl1.csv $ more rsl1.csv customer%0,quantity,amount,qtyNominal,amtNorminal A,1,10,-0.7071067812,-0.7071067812 A,2,20,0.7071067812,0.7071067812 B,1,15,-0.5773502692,0 B,3,10,1.154700538,-1 B,1,20,-0.5773502692,1
$ mnormalize c=Z k=customer f=quantity:qtyNominal,amount:amtNorminal i=dat1.csv o=rsl2.csv #END# kgnormalize c=Z f=quantity:qtyNominal,amount:amtNorminal i=dat1.csv k=customer o=rsl2.csv $ more rsl2.csv customer%0,quantity,amount,qtyNominal,amtNorminal A,1,10,42.92893219,42.92893219 A,2,20,57.07106781,57.07106781 B,1,15,44.22649731,50 B,3,10,61.54700538,40 B,1,20,44.22649731,60
$ mnormalize c=range k=customer f=quantity:qtyNominal,amount:amtNorminal i=dat1.csv o=rsl3.csv #END# kgnormalize c=range f=quantity:qtyNominal,amount:amtNorminal i=dat1.csv k=customer o=rsl3.csv $ more rsl3.csv customer%0,quantity,amount,qtyNominal,amtNorminal A,1,10,0,0 A,2,20,1,1 B,1,15,0,0.5 B,3,10,1,0 B,1,20,0,1
| MCMD2 |