| MCMD2 |
| MCMD2 |
The format of the parameters used in M-Command is slightly different than UNIX commands. The keyword and specified value is separated by an equal sign i.e. "keyword=value". Option type parameters precedes with a minus sign e.g. "-keyword" and do not require specified value.
Many parameters share common functions in M-Command. The parameters are explained below. However, in some command, it works as a completely different function.
Keyword Description Input file name Output file name Input and output field name Key field name Sort field name Add item name CSV without field name Output without field name Specify the field number Disable automatic sorting Number of significant figures Work file storage path name Delimiter of vector data Number of buffers --help Display help
Specify the name of input file. Most commands only allow a single file to be specified, with the exception of mcat command where multiple files can be specified separated with a comma. Yet, certain commands such as mnewnumber and mnewrand do not require input data.
When this parameter is not defined, data is read from standard input by using pipeline. In the example below, i= parameter is not specified for msum command because the input data is the result of msortf, which is read from standard input through the pipeline.
$ msortf f=a i=dat.csv | msum k=a f=b o=rsl.csv
However, it is difficult to identify errors when results are piped directly from one command to the next. In the following example, i= parameter is also specified for msum. The results of msortf is sent to standard output, and msum reads input data from dat.csv. Since msortf did not add meaning to the input for msum, the results from this example is different from the above.
$ msortf f=a i=dat.csv | msum k=a f=b i=dat.csv o=rsl.csv
Run mcut using dat1.csv as input data.
$ more dat1.csv customer,quantity,amount A,1,10 A,2,20 $ mcut f=customer,amount i=dat1.csv o=rsl1.csv #ERROR# field name not found: `customer' in dat1.csv (kgcut) $ more rsl1.csv
Read standard input using redirection (""<"").
$ mcut f= customer, amount o=rsl2.csv <dat1.csv #ERROR# invalid argument: customer, (kgcut) $ more rsl2.csv rsl2.csv: No such file or directory
The parameter can be used in all commands except for commands such as mnewnumber and mnewrand.
Specify the name of output file. Most commands only allow specification of a single file name, with the exception of mtee command where multiple files can be specified. There is also the command that does not require output data, for example, msep.
When this parameter is not defined, data is read from standard input through pipeline. In the following example o= is not specified in msortf because the output data is sent to standard output through pipeline.
$ msortf f=a i=dat.csv | msum k=a f=b o=rsl.csv
The example below is similar to the above. The difference is that o= parameter is specified for the msortf and the result of msortf is saved to tmp.csv. Even though the two commands are connected with pipeline, there is no data stream from standard output to msum, the receiving process could not read data from pipeline and stays idle.
$ msortf f=a i=dat.csv o=tmp.csv | msum k=a f=b o=rsl.csv
Below is a more complicated example by using mtee to connect the data streams between the two commands.
$ msortf f=a i=dat.csv | mtee o=tmp.csv | msum k=a f=b o=rsl.csv
The mtee command writes to a standard input file specified at o= and send the data to standard output concurrently. The results of msortf is written to tmp.csv, at the same time, msum receives the data stream through pipeline from mtee. The final result is saved to rsl.csv.
The result of mcut is saved to rsl1.csv as specified in o= parameter.
$ more dat1.csv customer,quantity,amount A,1,10 A,2,20 $ mcut f=customer,amount i=dat1.csv o=rsl1.csv #ERROR# field name not found: `customer' in dat1.csv (kgcut) $ more rsl1.csv
Write to standard input using redirection (">").
$ mcut f=customer,amount i=dat1.csv >rsl2.csv #ERROR# field name not found: `customer' in dat1.csv (kgcut) $ more rsl2.csv
This parameter can be used in all commands except for certain commands such as sep.
Specify the input and output field name for processing. For example, this parameter specifies the "field name to select" in mcut, "field name to aggregate" for magg, and "field name to merge" for mjoin. In addition, multiple field names can be specified separated by a comma in between such as f=a,b,c.
The output field name for every specified item from the input file can be renamed in MCMD. This can be done by defining the input field name and output field name separated by a colon in between e.g. f=a:A,b:B. The field name in the output remains the same if the output field name is not specified.
Extract fields val1 and val2.
$ more dat1.csv id,val1,val2 A,1,2 B,2,3 C,3,4 $ mcut f=val1,val2 i=dat1.csv o=rsl1.csv #END# kgcut f=val1,val2 i=dat1.csv o=rsl1.csv $ more rsl1.csv val1,val2 1,2 2,3 3,4
Aggregate val1,val2, and rename the fields in the output as sum1,sum2 respectively.
$ msum f=val1:sum1,val2:sum2 i=dat1.csv o=rsl2.csv #END# kgsum f=val1:sum1,val2:sum2 i=dat1.csv o=rsl2.csv $ more rsl2.csv id,sum1,sum2 C,6,9
Specify the key field name. A key field uniquely identifies individual rows or an entity in the data, it is used as unit of aggregation, or used as common key for joining fields between two files.
For example, in msum command, aggregate computation is carried out for records with the same key (aggregate key break processing). Whereas in mjoin command, the size of key items in the two data files are compared (join key break processing) and joined.
When k= command is specified, the field(s) specified are first sorted in character string ascending order, afterwards, corresponding processing is carried out.
and is considered as the default field for sorting character strings in ascending order (except for mhashsum). Key break process refers to the processing method for every same key field with the same value assuming that the items are sorted beforehand (However, mhashsum command is an exception).
For details on key break process, please refer to Key break processing. Since frequent sorting may decrease the processing performance, understanding the need for key break processing would help reduce the instances for sorting, desirable for optimizing script performance.
Compute sum on val column by id.
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ msum i=dat1.csv k=id f=val o=rsl1.csv #END# kgsum f=val i=dat1.csv k=id o=rsl1.csv $ more rsl1.csv id%0,val A,3 B,6
Use the join key “id” from dat1.csv, and join the field “name” from ref1.csv.
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ more ref1.csv id,name A,nysol B,mcmd $ mjoin k=id i=dat1.csv m=ref1.csv f=name o=rsl4.csv #END# kgjoin f=name i=dat1.csv k=id m=ref1.csv o=rsl4.csv $ more rsl4.csv id%0,val,name A,1,nysol A,2,nysol B,1,mcmd B,2,mcmd B,3,mcmd
msum, mslide, mjoin, mrjoin, mcommon, etc.
Specify the field name for sorting (multiple fields can be specified).
The order of records affects the process results for some commands such as maccum. When s= parameter is specified, sorting is carried out on the specified fields before the processing command.
There are four combinations of sorting methods (order), including numeric / string, and ascending / descending order. The sorting methods can be specified by appending % followed by n or r after the column name. The examples are as follows.
Character string ascending order: field (% not required), character string descending order: f=field%r, numeric ascending order: f=field%n, numeric descending order:f=field%nr.
After sorting by id, calcuate the cumulative sum on val column.
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ maccum s=id k=id f=val:val_accum i=dat1.csv o=rsl1.csv #END# kgaccum f=val:val_accum i=dat1.csv k=id o=rsl1.csv s=id $ more rsl1.csv id,val,val_accum A,1,1 A,2,3 B,1,1 B,2,3 B,3,6
After sorting the val field in descending numerical order, calculate the cumulative sum on val column.
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ maccum s=id,val%nr k=id f=val:val_accum i=dat1.csv o=rsl1.csv #END# kgaccum f=val:val_accum i=dat1.csv k=id o=rsl1.csv s=id,val%nr $ more rsl1.csv id,val,val_accum A,2,2 A,1,3 B,3,3 B,2,5 B,1,6
maccum, mbest, mmvavg, mnumber, mslide, etc.
Add an additional field (column) according to the field name specified. Most commands add the result in 1 field, thus, only 1 field is specified at this parameter. Nevertheless, mcombi returns multiple fields as output, thus multiple field names are specified delimited by comma.
Add a new field as “payday”.
$ more dat1.csv id A B C $ msetstr v=20070101 a=payday i=dat1.csv o=rsl1.csv #END# kgsetstr a=payday i=dat1.csv o=rsl1.csv v=20070101 $ more rsl1.csv id,payday A,20070101 B,20070101 C,20070101
Enumerate the two combination of each item A,B,C in the column “id”.
$ mcombi f=id n=2 a=id1,id2 i=dat1.csv o=rsl2.csv #END# kgcombi a=id1,id2 f=id i=dat1.csv n=2 o=rsl2.csv $ more rsl2.csv id,id1,id2 C,A,B C,A,C C,B,C
mcal, mcombi, mrand, msetstr etc.
This option reads input data without field names. When this option is specified, the field number is used instead of the field name to specify the field. The field number begins from the integer 0 and increments by 1 from the left onwards. When --nfn option is specified, the field name will not be included in the output file.
Extract column0 and 2.
$ more dat1.csv A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ mcut -nfn f=0,2 i=dat1.csv o=rsl1.csv #END# kgcut -nfn f=0,2 i=dat1.csv o=rsl1.csv $ more rsl1.csv A,10 A,20 B,15 B,10 B,20
This option can be used in all M-Commands except mchkcsv.
This option allow users to remove field names from the output data. Unlike --nfn, this option assumes that input data specified at i= and m= includes field names in the first row.
Extract column0 and 2.
$ more dat1.csv A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ mcut -nfn f=0,2 i=dat1.csv o=rsl1.csv #END# kgcut -nfn f=0,2 i=dat1.csv o=rsl1.csv $ more rsl1.csv A,10 A,20 B,15 B,10 B,20
This option can be used in all commands except mchkcsv.
This option allows user to specify a column with corresponding field number where input data includes field names. Users can specify the output field name(s) by adding colon right after input field, followed by the output field name.
Compute the sum of all items in column 1 and 2 of the same key.
$ more dat1.csv customer,quantity,amount A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ msum -x k=0 f=1,2 i=dat1.csv o=rsl1.csv #END# kgsum -x f=1,2 i=dat1.csv k=0 o=rsl1.csv $ more rsl1.csv customer,quantity,amount A,3,30 B,5,45
Rename column 1 and 2 as a,b respectively.
$ msum -x k=0 f=1:a,2:b i=dat1.csv o=rsl2.csv #END# kgsum -x f=1:a,2:b i=dat1.csv k=0 o=rsl2.csv $ more rsl2.csv customer,a,b A,3,30 B,5,45
The -nfn option assumes data starts from the first row when computing the sum of "quantity" and "amount". However, the result will not be computed as expected since the position of first row of data is defined differently when using -x and -nfn.
$ msum -nfn k=0 f=1,2 i=dat1.csv o=rsl3.csv #END# kgsum -nfn f=1,2 i=dat1.csv k=0 o=rsl3.csv $ more rsl3.csv customer,0,0 A,3,30 B,5,45
This option can be used in all commands except mchkcsv.
Use this option to disable automatic sorting on fields specified at k= parameter.
The s= option is not required when k= parameter is defined at the same time, therefore, each command operates the same as MCMD Ver. 1.0.
Find out the cumulative value by id field. When -q option is specified, sorting by field specified at k= parameter will be disabled.
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ maccum -q k=id f=val:val_accum i=dat1.csv o=rsl1.csv #END# kgaccum -q f=val:val_accum i=dat1.csv k=id o=rsl1.csv $ more rsl1.csv id,val,val_accum A,1,1 B,1,1 B,2,3 A,2,2 B,3,3
This function is available in all commands where k= parameter exists.
Applies sprintf format ["%.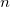 g"] in C language. This format converts the number of significant figures defined from normalized notation (integer bits, decimal bits: ex.123.456) to exponent notation (mantissa e
g"] in C language. This format converts the number of significant figures defined from normalized notation (integer bits, decimal bits: ex.123.456) to exponent notation (mantissa e exponent part: ex. 1.23456e+02). The criteria to adopt exponent notation for conversion is when the exponent bits exceed the specified number of significant digits or if it is less than or equal to -5 (i.e more than 4 zeros after decimal points).
exponent part: ex. 1.23456e+02). The criteria to adopt exponent notation for conversion is when the exponent bits exceed the specified number of significant digits or if it is less than or equal to -5 (i.e more than 4 zeros after decimal points).
Integers between 1 to 16 can be specified in , the default value is 10. When 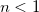 , set
, set 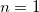 , and when
, and when  set to
set to 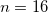 .
.
In addition, the number of significant figures can be changed by setting the environment variable KG_Precision. However, changes to the environment variable will affect the execution of all commands.
The exponential notation of id=1 is 1.2345678e +08, the exponent bits is more than 6 significant figures when the significant figures of mantissa is set at 6. The exponential notation of id=2 is 1.23456789e +03, the exponent bits is more than 7 significant figures when the significant figures of integer bits + decimal bits is set at 6. The exponential notation of id=4 is 1.23456789e-04, the exponent bits is less than -4 when the significant figures is set at 6. The exponential notation of id=5 is 1.23456789e-05, the exponent bits is less than -4 when the significant figures of mantissa is set at 6.
$ more dat1.csv
id,val
1,123456789
2,1234.56789
3,0.123456789
4,0.000123456789
5,0.0000123456789
$ mcal c='${val}' a=result precision=6 i=dat1.csv o=rsl1.csv
#END# kgcal a=result c=${val} i=dat1.csv o=rsl1.csv precision=6
$ more rsl1.csv
id,val,result
1,123456789,1.23457e+08
2,1234.56789,1234.57
3,0.123456789,0.123457
4,0.000123456789,0.000123457
5,0.0000123456789,1.23457e-05
$ mcal c='${val}' a=result precision=2 i=dat1.csv o=rsl2.csv
#END# kgcal a=result c=${val} i=dat1.csv o=rsl2.csv precision=2
$ more rsl2.csv
id,val,result
1,123456789,1.2e+08
2,1234.56789,1.2e+03
3,0.123456789,0.12
4,0.000123456789,0.00012
5,0.0000123456789,1.2e-05
When the environment variable is set, the setting will be applied to all commands in subsequent processes.
$ export KG_Precision=4
$ mcal c='${val}' a=result i=dat1.csv o=rsl3.csv
#END# kgcal a=result c=${val} i=dat1.csv o=rsl3.csv
$ more rsl3.csv
id,val,result
1,123456789,1.235e+08
2,1234.56789,1235
3,0.123456789,0.1235
4,0.000123456789,0.0001235
5,0.0000123456789,1.235e-05
This setting applies to all commands for calculating real numbers which is used in msum,mcal.
Specify the name of the directory which stores the temporary files for use by the command. For example, the results from msortf is saved as a temporary file during partitioned sort. If the path is not specified, the file is saved in /tmp. The name of temporary files begins with __KGTMP.
The temporary files are deleted if the command terminates normally (includes termination by exit signal, or termination by signal from MCMD signal). Temporary files will be retained in the directory when the program is terminated unexpectedly by power outage or bug.
Depending on the amount of data, enormous amount of temporary data may be generated (more than 1 million files). This will significantly slow down the execution of commands, therefore, clean out the files in the temporary path on a regular basis. Currently there is no plans to implement functions for garbage collection to remove objects no longer used by the program.
The temporary directory can be changed by setting the environment variable KG_Tmp_Path, however, the same variable applies to the execution of all commands.
Set the tmp directory under the current directory for temporary files.
$ msortf f=val tmpPath=./tmp i=dat1.csv o=rsl1.csv #END# kgsortf f=val i=dat1.csv o=rsl1.csv tmpPath=./tmp
The settings of the environment variable will be applied to subsequent commands.
$ export KG_TmpPath=~/tmp $ msortf f=val i=dat1.csv o=rsl1.csv #ERROR# internal error: cannot create temp file (kgsortf)
This applies to commands such as msortf and mdelnull which select records by key field, and commands such as mbucket, mnjoin, and mshare that require multiple pass scanning based on key field.
Specify the delimiter for elements in vector data. The default delimiter is 1 byte space. When comma is specified as the delimiter for the vector, the vector is enclosed in double quotes to avoid confusion with the comma delimiter in CSV file.
Sort the elements of the vector field “vec” with colon as a delimiter.
$ more dat1.csv vec b:a:c x:p $ mvsort vf=vec delim=: i=dat1.csv o=rsl1.csv #END# kgvsort delim=: i=dat1.csv o=rsl1.csv vf=vec $ more rsl1.csv vec a:b:c p:x
Since delim parameter is not specified, b:a:c and x:p is interpreted as one element.
$ mvsort vf=vec i=dat1.csv o=rsl2.csv #END# kgvsort i=dat1.csv o=rsl2.csv vf=vec $ more rsl2.csv vec b:a:c x:p
If comma is used as delimiter for the vector, the entire vector is enclosed by double quote to draw distinction between the delimiter of CSV and the delimiter of the vector.
$ more dat2.csv id,vec1,vec2 1,a,b 2,p,q $ mvcat vf=vec1,vec2 a=vec3 delim=, i=dat2.csv o=rsl3.csv #END# kgvcat a=vec3 delim=, i=dat2.csv o=rsl3.csv vf=vec1,vec2 $ more rsl3.csv id,vec3 1,"a,b" 2,"p,q"
This parameter can be used in all vector related commands such as such as mvcat and mvsort.
Specify the internal buffer size (number of blocks) to be used in commands such as mbucket, mnjoin, and mshare, for processing key units at which data requires multiple pass scanning. One buffer block contains 4MB, the default size is 10 blocks (40MB). In case of buffer overflow, data is written to a temporary file. If the key size is very large, the processing speed can be improved by adjusting this parameter if memory permits.
If the key size of the reference file is less than 80MB (4MB × 20), the temporary file will not be used.
$ mnjoin k=id m=ref.csv f=name i=dat.csv o=rsl.csv bufcount=20 #END# kgnjoin bufcount=20 f=name i=dat.csv k=id m=ref.csv o=rsl.csv
Commands that require multiple pass scanning of the data to process key units, such as mbucket, mnjoin, and mshare.
| MCMD2 |