9. メソッドの自動追加¶
いくつかのmcmdメソッドを登録し、run メソッドで実行する前に、
自動的にmcmdメソッドが追加されることがある。
以下では、その条件と内容について説明する。
9.1. キーブレイク処理に伴うmsortfの追加¶
キーブレイク処理(キー項目単位の処理)を利用しているメソッドの前にmsortfメソッドが自動追加される。
各メソッドのマニュアルには、msortfメソッドが自動追加されるかどうかが明記されている。
キー単位のイテレータ keyblock や k= を指定した getline メソッドも対象となる。
msortfメソッドの自動追加を抑制したい場合は q=True を指定すればよい。
リスト 9.1 に msum メソッドを使った例を示している。
q=True を指定すると、入力データの順序でキーブレイク処理が行われていることがわかる。
なお、msortfの自動追加機能は各メソッドに組み込まれた機能であるため、
drawModelsDS 等で内容を表示させても出力されず、
また実行時にメッセージを表示させてもmsortfのENDメセージは表示されない。
1>>> import nysol.mcmd as nm 2>>> dat=[ 3["customer","amount"], 4["A",5200], 5["B",800], 6["B",3500], 7["A",2000], 8["B",4000] 9] 10>>> f1=nm.msum(k="customer",f="amount",i=dat) 11>>> f1.run() 12[['A', '7200'], ['B', '8300']] 13>>> f2=nm.msum(k="customer",f="amount",i=dat,q=True) 14>>> f2.run() 15[['A', '5200'], ['B', '4300'], ['A', '2000'], ['B', '4000']]
キーブレイク処理¶
キーブレイク処理とは、その項目が並べ換わっていることを前提として、 同一のキー項目値毎に一定の処理を行う処理方式のことを言う。 キーブレイク処理は大きく分けて2つの方式に分けられる。 一つは集計のためのキーブレイク処理( 集計キーブレイク処理 と呼ぶ)で、 他方は結合のためのキーブレイク処理( 結合キーブレイク処理 と呼ぶ)である。
mjoin や mcommon など
メソッド名に「join」か「common」を含むメソッドが結合キーブレイク処理を、
それ以外のメソッドのうち k= パラメータを持つ全てのメソッドが
集計キーブレイク処理を行っていると考えてよい。
たとえば集計キーブレイク処理を行う msum では、
キー項目の値の変化を検知することで、同一キー毎に合計処理を実行する。
そのためには事前にキー項目で行の並べ替えをしておく必要があるので、
(入力ファイルが事前に並べ替えられている場合を除き) msum 内部で
ソーティング処理を追加した上で合計処理を行う。
結合キーブレイク処理はもう少し複雑で、たとえば mjoin は、
2つのデータファイルについて、キー項目の大小を見比べる。
キー項目が小さいデータファイルは読み進め、キー項目値が同じであれば結合処理を実施する。
このようにキー項目値の大小比較をしているため、結合のためのキーブレイク処理においては、
事前に2つのデータファイルともキー項目で並べ替えられていることが前提となる。
そのため mjoin では、まず内部で2つのデータファイルをソーティングする処理が追加される。
どちらのキーブレイク処理でも基本は文字列昇順による並べ替えを行うが、
mrjoin のような数値範囲による結合キーブレイク処理においては、
数値昇順で並べ替えを行う。
k= で項目を指定するだけで、各メソッドが自動的に並べ替えの要否を
判断し、必要な場合は並べ替えを行うため、ユーザは原則としてファイルの並べ替えを
意識する必要はない。ただ並べ替え処理が不要になったわけではなく、
各メソッドが内部的に並べ替え処理を行っているという点に注意が必要である。
スクリプトの構成によっては、並べ替え処理が頻繁に発生し、パフォーマンス低下の原因となることもある。
リスト 9.2 に例を示す。
これは、どの顧客( customer )が、いつ( date )、どの店( store )で買物をしたかのリスト( purchase )に、
別に用意された3つのリスト、顧客名( custName )、年令( age )、店名( storeName )を結合する単純な処理である。
f1 の処理フローでは、結合キーの順番が customer , store , customer の順になり、3回のソーティングが実行されるが、
f2 の処理フローでは、結合キーの順番が customer , customer , store の順になり、2回目の結合キーが1回目と同じためにソーティングが1回少なくて済む。
1import nysol.mcmd as nm
2
3purchase=[
4["customer","date","store"],
5["A","20181019","p"],
6["B","20181019","q"],
7["B","20181022","q"],
8["A","20181021","q"],
9["B","20181023","p"]
10]
11
12custName=[
13["customer","custName"],
14["A","Ken"],
15["B","Lisa"]
16]
17
18age=[
19["customer","age"],
20["A",30],
21["B",28]
22]
23
24storeName=[
25["store","storeName"],
26["p","TokyoStore"],
27["q","OsakaStore"]
28]
29
30f1=None
31f1 <<= nm.mjoin(k="customer", m=custName, i=purchase)
32f1 <<= nm.mjoin(k="store", m=storeName)
33f1 <<= nm.mjoin(k="customer", m=age)
34result1=f1.run(msg="on")
35print(result1)
36# [['A', '20181019', 'p', 'Ken', 'TokyoStore', '30'], ['A', '20181021', 'q', 'Ken', 'OsakaStore', '30'], ['B', '20181023', 'p', 'Lisa', 'TokyoStore', '28'], ['B', '20181019', 'q', 'Lisa', 'OsakaStore', '28'], ['B', '20181022', 'q', 'Lisa', 'OsakaStore', '28']]
37
38f2=None
39f2 <<= nm.mjoin(k="customer", m=custName, i=purchase)
40f2 <<= nm.mjoin(k="store", m=storeName)
41f2 <<= nm.mjoin(k="customer", m=age)
42result2=f2.run(msg="on")
43print(result2)
44# [['A', '20181019', 'p', 'Ken', '30', 'TokyoStore'], ['B', '20181023', 'p', 'Lisa', '28', 'TokyoStore'], ['A', '20181021', 'q', 'Ken', '30', 'OsakaStore'], ['B', '20181019', 'q', 'Lisa', '28', 'OsakaStore'], ['B', '20181022', 'q', 'Lisa', '28', 'OsakaStore']]
9.2. 入出力によるデータ変換¶
多くのmcmdメソッドでは、i= にリストを指定すると、そのリストデータを入力データとして読み込んでくれる。
一方で、mcmdメソッドは内部では全てのデータをテキストのバイトストリームとして扱っている。
そのため、リストをバイトストリームに変換する必要がある。
入力時にリストをバイトストリームに変換するメソッドが readlist で、
出力時にバイトストリームをリストに変換するメソッドが writecsv である。
そこで、i= にリストを指定した場合は readlist が追加され、
また出力先が明示的/暗黙的に指定されていなければ writelist が自動追加される。
1>>> import nysol.mcmd as nm 2>>> dat=[ 3["customer","amount"], 4["A",5200], 5["B",800], 6["B",3500], 7["A",2000], 8["B",4000] 9] 10>>> f=nm.msum(k="customer",f="amount",i=dat) 11>>> f.drawModelD3("autoadd_list.html") 12>>> f.run() 13[['A', '7200'], ['B', '8300']]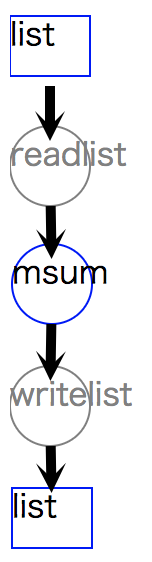
図 9.1 readlistとwritelistが自動追加された処理フロー¶
同様にCSVファイルをバイトストリームに変換するメソッドとして、 readcsv と writecsv がある。
ただし、mcmdメソッドでは、i= o= にファイル名を指定する一般的な使い方であれば、メソッド内部でこの変換が行われるため、
readcsv や writecsv が自動追加されることはない。
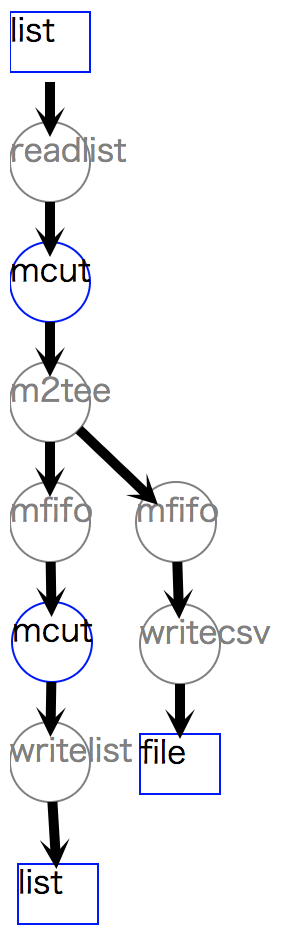
writecsv が自動追加される典型例は、フローの途中で o=ファイル名 を指定することである。
リスト 9.4 にその例を示している。
これは2つの mcut をつなげただけの意味のない単純なフローである。
最初の mcut でその途中経過をCSVファイル tmp.csv に出力しており、
m2tee の追加でストリームを2分岐させ(後述)、mfifo でバッファリングをかませた上で(後述)、
一方を writecsv に他方を mcut に接続している。
9.3. 処理フローの併合によるm2catの追加¶
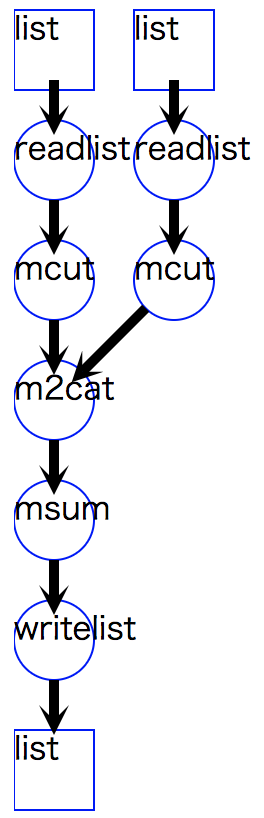
2つの処理フローの出力データを併合(行方向にまとめる)したい場合、
mcmdメソッドで i=[obj1,obj2,... のように i= に複数の処理フローオブジェクトをリストで与えることによって実現できる。
その時、これら複数のフローから出力されるデータを併合するメソッドとして m2cat が自動挿入される。
リスト 9.5 には、1つの``mcut`` から構成される2つの処理フローオブジェクト f1 と f2 を
msum メソッドの入力として指定している。
この場合、msum の前に m2cat が挿入される。
9.4. フロー分岐によるm2tee,mfifoの追加¶
m2cat の自動追加とは逆に、ある1つのフローの出力が複数のフローの入力として接続される場合、
m2tee および mfifo が自動追加される。
m2tee は入力ストリームを複数のストリームに分岐させる機能を担い、
mfifo はデッドロックを回避する目的で、データバッファの機能を担う(First In First Out buffer)。
リスト 9.6 では、顧客別に amount の構成比を計算する処理を示している。
ポイントは、1行目の mcut の出力は、 msum (2行目)と mjoin (3行目) の2つのメソッドに接続されている点である。
それに伴い、 mcut の後に m2tee が挿入されることでデータフローが分岐している。
1>>> f=nm.mcut(f="customer,amount",i=dat) 2>>> total=nm.msum(k="customer", f="amount:totalAmount",i=f) 3>>> f <<= nm.mjoin(k="customer", m=total, f="totalAmount") 4>>> f <<= nm.mcal(c='${amount}/${totalAmount}', a="share") 5>>> f.drawModelD3("autoadd_mtee.html") 6>>> f.run() 7[['A', '5200', '7200', '0.7222222222'], ['A', '2000', '7200', '0.2777777778'], ['B', '800', '8300', '0.09638554217'], ['B', '3500', '8300', '0.421686747'], ['B', '4000', '8300', '0.4819277108']]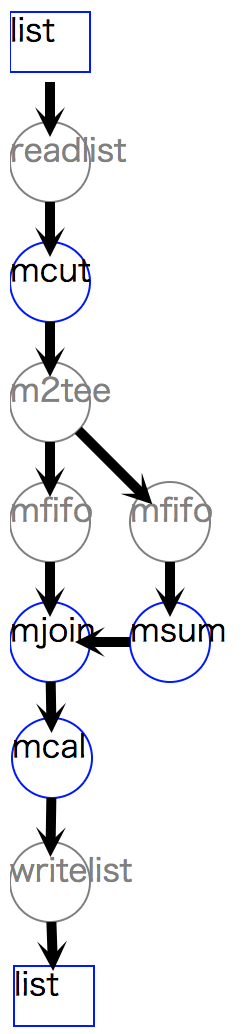
図 9.4 m2tee,mfifoが自動追加された処理フロー¶
分岐後それぞれに mfifo が追加されているが、このバッファがなければどうなるであろうか?
m2tee は単純に1つの入力を1行ずつ2つの出力にコピーしているだけで、いずれかの出力先に渋滞が起こると待ちが生じることになる。
ここでは簡単のために、ある入力行を両方に出力できて初めて次の行の処理ができるとしよう。
これは分岐先のいずれかのメソッドがデータを受け取りに来なければ、 m2tee は待ち状態になるということである。
一方で、分岐後の mjoin は msum の結果を結合しており、 msum からの出力が来るまでは待ち状態になる。
もう一点抑えておくべきことは、 mfifo , msum , mjoin は実行時には並列で動作するため、
どのメソッドがどのタイミングで実行されるかは不定であるということである。
これらを合わせて考えると、 mtee がある顧客の最初の行を mjoin に渡すと、 mjoin は msum からの出力待ちのため止まってしまう。
一方で msum はその顧客の全行を処理しないと結果を mjoin に渡せない。
ところが、mtee は mjoin が待ちのために止まってしまっていて、msum は mtee からデータの供給を絶たれるわけである。
このようにお互いの処理からのデータを互いに待ってしまい、全体としての処理が次に進めないことをデッドロックと呼ぶ。
実際には m2tee がある程度のバッファを持っているために、即座にデッドロックが起こるわけではないが、
顧客あたりのデータ件数が多くなると m2tee のバッファが満杯となりデッドロックが起こる可能性がでてくる。
mfifo はこのようなデッドロックを回避する目的で追加される。
mfifo はメソッド内部で無限のバッファを持っていると考えればよい。
実際にはある一定の大きなメモリとそのメモリが一杯になったときは、ファイルバッファに切り替える。
このことで、 m2tee は分岐後の処理を気にせず、無限容量のあるバッファに単純にコピーしていくことになり、
そこでデータの渋滞が起こることはなくなり、結果としてデッドロックが回避される。
実は、mfifo の追加は、以上のようなデッドロックを起こすロジックを検出しているわけではなく、
mtee によりデータの分岐が生じた時にはデッドロックを引き起こさないロジックであったとしても、必ず追加するようにしている。
mfifo 自体は、バッファが一杯にならない限り、メモリ内でデータを右から左に流しているだけなので、非常に高速で、
このような冗長な方法で自動追加しても十分にペイする。
上述の分岐の例以外にも、redirectを用いた分岐がある。この場合も同様に m2tee と mfifo が自動追加される。
リスト 9.7 にその例を示す。
この例では、最初に mselstr メソッドにて、顧客 A とそれ以外に分割し、
A以外の顧客は amount が1000以上の行のみを選択し、
分割しておいた顧客 A と併合した後に、 amount の合計を計算するというものである。
この例でのポイントは、mselstr の処理にて、
条件にマッチする出力 o= とアンマッチ出力 u= の2つに分岐させている点である。
u= のストリームは redirect 関数によって実現されている。
ただし、 redirect 関数は、それ自体で何らかの処理を実行するものではなく、
ストリームのつなげ変えを行うだけなので処理フローの図には表示されない。
上述の例と同様に、分岐後に m2tee と mfifo が自動挿入されているのがわかる。
1>>> custA =nm.mselstr(f="customer",v="A",i=dat) 2>>> custB =custA.redirect("u") 3>>> custB <<=nm.mselnum(f="amount",c='[1000,]') 4>>> cat =nm.m2cat(i=[custA,custB]) 5>>> cat<<=nm.msum(k="customer",f="amount") 6>>> cat.run() 7>>> cat.drawModelD3("autoadd_redirect.html") 8[['A', '7200'], ['B', '7500']]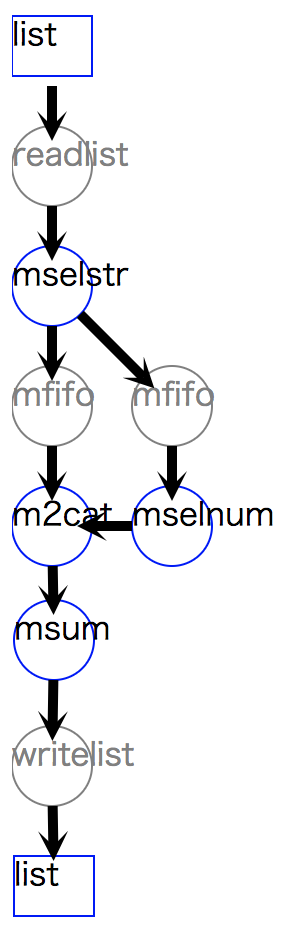
図 9.5 redirectによってm2tee,mfifoが自動追加された処理フロー¶