4. 処理フロー¶
mcmdでは、単一機能に特化した80以上の処理メソッドを自由に組み合わせることで、
データ処理の複雑なフローを構築することができ、それらは並列で処理される。
このようなフロー全体のことを データ処理フロー もしくは単に 処理フロー と呼ぶ。
そして処理フローを扱うオブジェクトを データ処理フローオブジェクト もしくは単に 処理フローオブジェクト と呼ぶ。
処理フローは、有向非循環グラフ( DAG :Directed Acyclic Graph)で表される。
DAGの節点が処理メソッドに、そして有向辺がデータの流れに対応する。
図 4.1 はいずれもDAGで表された処理フローである。
(a)や(b)は比較的単純な構造の処理フローであるが、(c)のような複雑な処理フローも実現可能である。
処理フローにおいて、いずれからも入力のない節点をソース節点と呼び、いずれの節点にも出力のない節点をシンク節点と呼ぶ。
図 4.1 では、ソース節点が赤枠で示され、シンク節点が青色で示されている。
ソース節点には、必ず入力データが指定されなければならす、シンク節点には必ず出力データが指定されなければならない
(後述するように、出力データの指定は省略できる)。
また、シンク節点の数により、処理フローの実行方法が異なり、
シンク節点が1つだけの処理フローは run メンバーメソッドで、複数ある場合は runs クラスメソッドで実行する。
それぞれのメソッド詳細については「 runとruns 」の節を参照されたい。
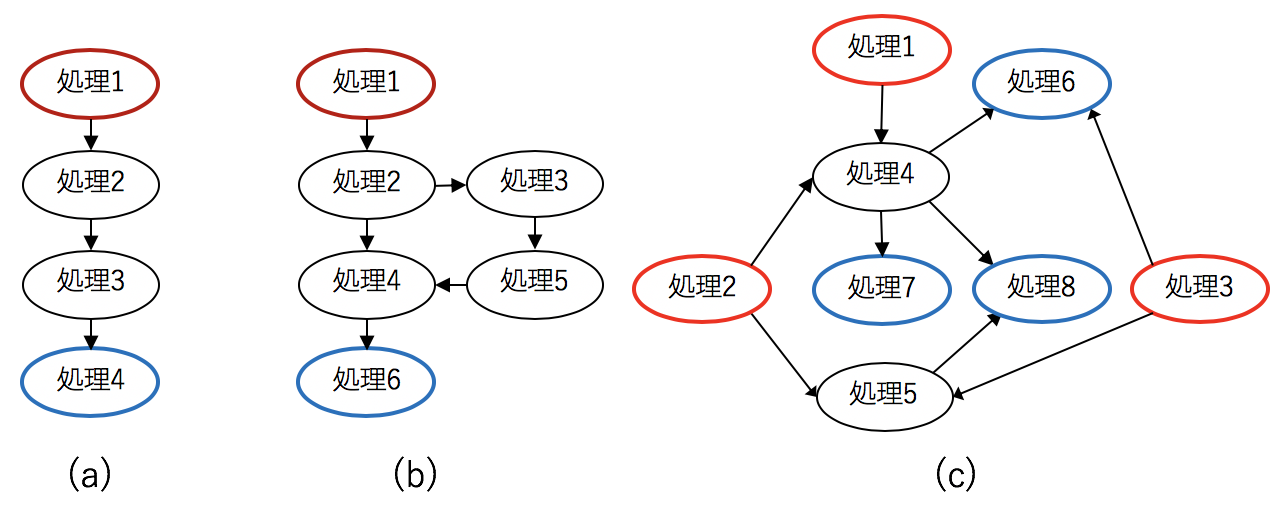
図 4.1 DAG(有向非循環グラフ)で表される処理フロー¶
以下では、単純な例から始め、mcmdがデータ処理フローをどのように構成していくかについて説明する。
4.1. 暗黙の接続¶
単純なデータ処理フローから始めよう。
図 リスト 4.1 は、「 はじめよう 」節の リスト 1.4 に示したフローである。
2重リストに格納された3項目5行のデータを入力データとして、
mcut メソッドにより、 customer と amount 項目のみを切り出し、
amount 項目を合計するというものである。
1>>> import nysol.mcmd as nm 2>>> dat=[ 3["customer","date","amount"], 4["A","20180101",5200], 5["B","20180101",800], 6["B","20180112",3500], 7["A","20180105",2000], 8["B","20180107",4000] 9] 10>>> f=None 11>>> f <<= nm.mcut(f="customer,amount",i=dat) 12>>> f <<= nm.msum(k="customer",f="amount") 13>>> f.run() 14[['A', '7200'], ['B', '8300']]
<<= 演算子により、左辺の処理フローオブジェクトに右辺の処理メソッドが追加登録される。
左辺が None の場合は、新規に処理フローオブジェクトが生成され、右辺の処理メソッドが登録される。
登録順は重要で、明示的な接続関係(後述)を設定しなければ、前のメソッドの出力データが次のメソッドの入力データとして接続される。
このような接続方式を 暗黙の接続 と呼ぶ。
リスト 4.1 では、mcut の出力が msum の入力として暗黙に接続される。
そして、このように作成された処理フローの実行は f.run() のように、処理フローオブジェクト
f のメンバーメソッドである run を呼び出せばよい。
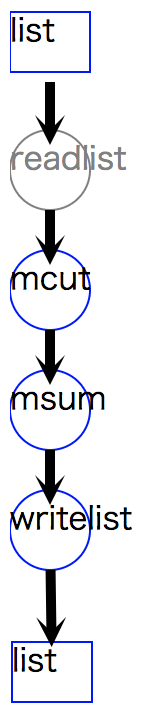
また、drawModelD3 メソッドを利用すれば処理フロー全体を視覚化することができる( リスト 4.2 )。
結果は 図 4.2 に示されるように、メソッドの接続関係がグラフで描画される。
円のノードでメソッドを、四角のノードでデータを表している。
また、メソッド名が薄字のものは、mcmdが実行時に裏で自動追加した処理を示しているが、ここでは無視して考えて問題ない。
処理の自動追加については「 メソッドの自動追加 」の節を参照されたい。
4.2. 明示的な接続¶
処理フローオブジェクトにおけるデータの流れを明示的に接続する方法はいくつかある。
mcmdが提供する処理メソッドの多くは、入出力のための共通したパラメータを持っている。
i= および m= は入力データを指定するパラメータで、
o= および u= は出力データを指定するパラメータである。
データストリームの接続は、入力のパラメータに処理フローオブジェクトを指定することで実現する。
いくつかの例を見てみよう。
項目結合の例¶
リスト 4.3 は顧客別( A と B )の合計金額を求め、それぞれの構成比を求める処理である。
1行目のフローオブジェクト f を2行目の msum の入力データに指定し( i=f )、
その処理内容を total という別の処理フローオブジェクトとして設定している。
total オブジェクトを4行目の mproduct の参照データに指定することで( m=total )、
合計金額項目 totalAmount が結合される。
3行目の msum の入力データは、同じフローオブジェクト f に対する追加になるため、
1行目の mcut の出力がそのまま接続される。
図 4.3 には、それらの接続関係が視覚化されている。
ここでも 自動追加 されたメソッドがあるが、それらは無視して構わない。
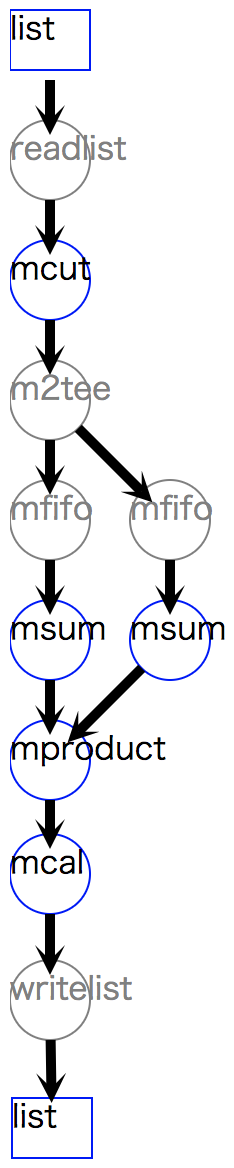
図 4.3 項目の結合の処理フロー¶
この例では、処理フローオブジェクト f における接続の多くは暗黙の接続である。
オブジェクト名を変えることで、これを明示的な接続へと変更することも可能である。
リスト 4.4 にその内容を示す。
フロー図は、 図 4.3 と同様である。
リスト 4.3 とは異なり、全てのメソッドに i= を指定することで
接続を明示的に指定しているのがわかるであろう。
なお、 run で実行する対象は、シンク節点である最後に登録された処理メソッドとなる。
リスト 4.4 において、 f4.run() を f3.run() にすれば、
当然、 mprodcut の結果までが出力されることになる。
1>>> f1 = nm.mcut(f="customer,amount", i=dat) 2>>> total=nm.msum(f="amount:totalAmount", i=f1) 3>>> f2 = nm.msum(k="customer", f="amount", i=f1) 4>>> f3 = nm.mproduct(m=total, f="totalAmount", i=f2) 5>>> f4 = nm.mcal(c='${amount}/${totalAmount}', a="share", i=f3) 6>>> f4.run() 7[['A', '7200', '15500', '0.464516129'], ['B', '8300', '15500', '0.535483871']]
レコード併合の例¶
データを種別で分割し、一方にはある処理を、他方には別の処理を付した上で両者を併合するといった処理はよく用いられる。
リスト 4.5 はそのような処理を例示したフローである。
msestr を2回使い、顧客 A と顧客 B を分割し、 B のみ amount が1000以上を選択し、
分割した2つのデータを msum メソッドの i= パラメータ指定にて併合している。
入力パラメータ i= の指定は [custA,custB] のように、処理フローオブジェクトのリストでなければならない。
1>>> f1=None 2>>> f1 <<= nm.mcut(f="customer,amount",i=dat) 3>>> custA = nm.mselstr(f="customer",v="A",i=f1) 4>>> custB = nm.mselstr(f="customer",v="B",i=f1) 5>>> custB <<= nm.mselnum(f="amount",c="[1000,]") 6>>> f2=None 7>>> f2 <<= nm.msum(k="customer", f="amount", i=[custA,custB]) 8>>> f2.drawModelD3("flow_merge.html") 9>>> f2.run() 10[['A', '7200'], ['B', '7500']]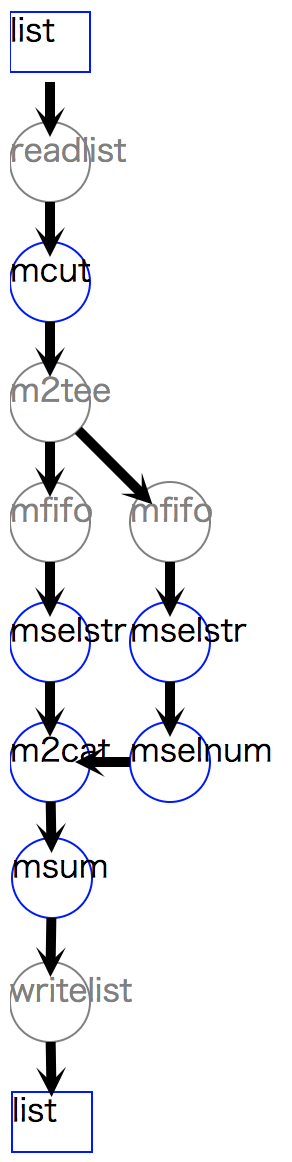
図 4.4 レコード併合の処理フロー¶
4.3. redirect¶
リスト 4.5 では、mselstr を2回用いているために、f1 の出力を2度読み込んでいることになり効率が悪い。
mselstr には条件にマッチした行の出力先を o= で指定する一方で、
アンマッチの行を u= で出力することができる。
この機能を使えば、 mselstr の実行は1回で済むことになる。
o= の出力は次に登録されるメソッドの入力となるが、 u= を次のメソッドに接続するにはどうすればよいであろうか?
それを実現するのが、 redirect メソッドである。
リスト 4.6 は、リスト 4.5 を redirect を用いて書き直したものである。
違いは4行目だけで、 custA.redirect("u") によって、 custA に登録された最後のメソッド( mselstr )の u= パラメータを
custB の処理フローオブジェクトに接続することになる。
図 4.5 を見てもわかるように、 mselstr は1回のみ実行されており、 リスト 4.5 より効率的に動作する。
1>>> f1=None 2>>> f1 <<= nm.mcut(f="customer,amount",i=dat) 3>>> custA = nm.mselstr(f="customer",v="A",i=f1) 4>>> custB = custA.redirect("u") 5>>> custB <<= nm.mselnum(f="amount",c="[1000,]") 6>>> f2=None 7>>> f2 <<= nm.msum(k="customer", f="amount", i=[custA,custB]) 8>>> f2.drawModelD3("flow_redirect.html") 9>>> f2.run() 10[['A', '7200'], ['B', '7500']]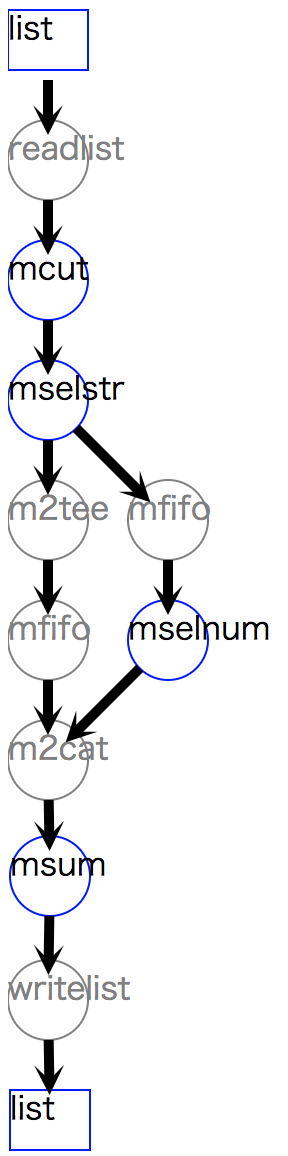
図 4.5 redirectを用いた例¶
4.4. runs: 複数の出力があるフローの実行¶
ここまでに扱ってきた例は、 図 4.1 の(a),(b)のように、全て最終出力が1つの処理フローであった。
ここでは出力が複数ある処理フローについて説明する。
リスト 4.7 にそのようなフローの一例を示している。
この例では、 mselstr にて、 customer 項目が A である行とそれ以外の行に分岐させ、
それぞれで amount 項目を合計するという処理を実行している。
分岐には、前述の redirect メソッドを使っている。
まず、このように複数の最終出力があるケースの実行には、 runs クラスメソッドを利用し、
引数に、最終出力を含むオブジェクトをリストで与える(例では nm.runs([fa,fb]) )。
runs は引数に与えられた処理フロー全てを統合し、全体の構造を識別した上で実行する。
そして、全体の処理フローに登録された処理メソッドをthreadに展開し並列処理で実行される。
ただし、同時にオープンできるthread数の上限等の制約があるので、詳細は「 runとruns 」の節を参照されたい。
runs の返り値は、出力されたCSVファイル名のリストである。
また、出力はCSVファイルだけでなく、 o=リスト のようにリストへの出力も可能である。
1>>> fa=None 2>>> fb=None 3>>> fa <<= nm.mcut(f="customer,amount",i=dat) 4>>> fa <<= nm.mselstr(f="customer",v="A") 5>>> fb <<= fa.redirect("u") 6 7>>> fa <<= nm.msum(k="customer",f="amount",o="out1.csv") 8>>> fb <<= nm.msum(k="customer",f="amount",o="out2.csv") 9 10>>> nm.runs([fa,fb],msg="on") 11#END# kgload -nfn; IN=0 OUT=5; 2018/09/09 15:22:45; 2018/09/09 15:22:45 12#END# kgselstr f=key v=a; IN=4 OUT=2; 2018/09/09 15:22:45; 2018/09/09 15:22:45 13#END# kgfifo; ; 2018/09/09 15:22:45; 2018/09/09 15:22:45 14#END# kgfifo; ; 2018/09/09 15:22:45; 2018/09/09 15:22:45 15#END# kgsum f=val k=key o=xxa; IN=2 OUT=1; 2018/09/09 15:22:45; 2018/09/09 15:22:45 16#END# kgsum f=val k=key o=xxb; IN=2 OUT=1; 2018/09/09 15:22:45; 2018/09/09 15:22:45 17# out1.csvの内容 18# key%0,val 19# a,3 20# out2.csvの内容 21# key%0,val 22# b,7
同じことを run を使っても実現は可能である。
そのコードは リスト 4.8 に示す通りである。
違いは、最後の2行のみで、2つの最終出力を伴う処理オブジェクトをそれぞれ run しているのである。
当然、出力結果も全く同じとなるが、違いは処理メッセージを見てもわかるように、
fa fb に共通した処理である mcut と mselstr が2回実行されている。
これは、 runsが、fa fb 両方の処理フローを統合して処理を実行する一方で、
run は、fa fb それぞれの入力から出力までのDAG上のパスをそれぞれで実行するため、
共通の処理メソッドも重複して実行されるのである。
1>>> fa=None 2>>> fb=None 3>>> fa <<= nm.mcut(f="customer,amount",i=dat) 4>>> fa <<= nm.mselstr(f="customer",v="A") 5>>> fb <<= fa.redirect("u") 6 7>>> fa <<= nm.msum(k="customer",f="amount",o="out1.csv") 8>>> fb <<= nm.msum(k="customer",f="amount",o="out2.csv") 9 10>>> fa.run(msg="on") 11#END# kgload -nfn; IN=0 OUT=6; 2018/09/10 06:10:20; 2018/09/10 06:10:20 12#END# kgselstr f=customer v=A; IN=5 OUT=2; 2018/09/10 06:10:20; 2018/09/10 06:10:20 13#END# kgsum f=amount k=customer; IN=2 OUT=1; 2018/09/10 06:10:20; 2018/09/10 06:10:20 14#END# kgload; IN=0 OUT=0; 2018/09/10 06:10:20; 2018/09/10 06:10:20 15[['A', '20180105', '7200']] 16>>> fb.run(msg="on") 17#END# kgload -nfn; IN=0 OUT=6; 2018/09/10 06:10:20; 2018/09/10 06:10:20 18#END# kgselstr f=customer v=A; IN=5 OUT=3; 2018/09/10 06:10:20; 2018/09/10 06:10:20 19#END# kgfifo; ; 2018/09/10 06:10:20; 2018/09/10 06:10:20 20#END# kgload; IN=0 OUT=0; 2018/09/10 06:10:20; 2018/09/10 06:10:20 21#END# kgsum f=amount k=customer; IN=3 OUT=1; 2018/09/10 06:10:20; 2018/09/10 06:10:20 22[['B', '20180107', '8300']]
4.5. 並列処理への応用¶
runs を使うことで、 SIMD(Single Instruction Multiple Data)型の並列処理を実現することも可能である。
あらかじめ同じタイプのデータを多数用意しておき、それらのデータに同一の処理を並列で実行するというものである。
簡単な例を リスト 4.9 に示そう。
ここでは、2つのデータ dat1 と dat2 を1つの配列 dat に格納し、
それらのデータを並列で合計処理するというものである。
データはリストで与えなくても、予め分割された多数のCSVファイルでも良い。
数十万ファイルを用意して実行することも可能である。
例では、for文で、 msum のみから構成される処理フローをリスト runlist に登録していき、
最後に、それらの処理フローを nm.runs(runlist) にて実行している。
runsは登録された全ての処理フローを解析し、
他の処理フローとつながりのない処理フローを島として確認する。
そして、それらの島をthreadに配置し実行するのである。
処理フローが独立であればお互いに干渉しないとの前提で実行するため、
例えば、複数の処理フローの最終ファイル名が同一であるような場合
(すなわち島が互いに干渉し合っていると)正しい結果は得られない。
1import nysol.mcmd as nm 2dat1=[ 3["key","val"], 4["a",1], 5["a",2], 6] 7 8dat2=[ 9["key","val"], 10["b",3], 11["b",4], 12] 13dat=[dat1,dat2] 14 15runlist=[] 16for i in range(len(dat)): 17 f=nm.msum(f="val",o="out%d.csv"%i) 18 runlist.append(f) 19nm.runs(runlist) 20# out0.csvの内容 21# key,val 22# a,3 23# out1.csvの内容 24# key,val 25# b,7
4.6. 途中の処理メソッドにo=を使うケース¶
複数の出力を伴う処理フローであっても、フローが分岐するのではなく、
処理フローの途中の処理メソッドに o=CSVファイル名 を指定するケースでは、
その処理メソッドはシンク節点とはならないので、 run で実行可能である。
分かりやすい例を リスト 4.10 に示している。
内容的には意味のないことではあるが、4つの msetstr で項目を1つずつ追加していっているだけである。
最後の msetstr 以外は、 o= で出力ファイル名を指定しているが、
そこまでの途中経過がそれぞれのファイルに出力される。
最後の msetstr は o= を指定していないのでリストで出力される。
1>>> f=None 2>>> f <<= nm.msetstr(v="out1",a="out1",i=dat,o="out1.csv") 3>>> f <<= nm.msetstr(v="out2",a="out2",o="out2.csv") 4>>> f <<= nm.msetstr(v="out3",a="out3",o="out3.csv") 5>>> f <<= nm.msetstr(v="out4",a="out4") 6>>> f.run() 7[['A', '20180101', '5200', 'out1', 'out2', 'out3', 'out4'], ['B', '20180101', '800', 'out1', 'out2', 'out3', 'out4'], ['B', '20180112', '3500', 'out1', 'out2', 'out3', 'out4'], ['A', '20180105', '2000', 'out1', 'out2', 'out3', 'out4'], ['B', '20180107', '4000', 'out1', 'out2', 'out3', 'out4']] 8# out1.csvの内容 9# customer,date,amount,out1 10# A,20180101,5200,out1 11# B,20180101,800,out1 12# B,20180112,3500,out1 13# A,20180105,2000,out1 14# B,20180107,4000,out1 15# out2.csvの内容 16# customer,date,amount,out1,out2 17# A,20180101,5200,out1,out2 18# B,20180101,800,out1,out2 19# B,20180112,3500,out1,out2 20# A,20180105,2000,out1,out2 21# B,20180107,4000,out1,out2 22# out3.csvの内容 23# customer,date,amount,out1,out2,out3 24# A,20180101,5200,out1,out2,out3 25# B,20180101,800,out1,out2,out3 26# B,20180112,3500,out1,out2,out3 27# A,20180105,2000,out1,out2,out3 28# B,20180107,4000,out1,out2,out3
これは、 o= にリストを指定しても同様である。
リスト 4.10 と同様の処理を o=リスト によって書き換えたコードを
リスト 4.11 に示す。
1>>> out1=[] 2>>> out2=[] 3>>> out3=[] 4>>> out4=[] 5>>> f=None 6>>> f <<= nm.msetstr(v="out1",a="out1",i=dat,o=out1) 7>>> f <<= nm.msetstr(v="out2",a="out2",o=out2) 8>>> f <<= nm.msetstr(v="out3",a="out3",o=out3) 9>>> f <<= nm.msetstr(v="out4",a="out4") 10>>> out4=f.run() 11>>> print(out1) 12[['A', '20180101', '5200', 'out1'], ['B', '20180101', '800', 'out1'], ['B', '20180112', '3500', 'out1'], ['A', '20180105', '2000', 'out1'], ['B', '20180107', '4000', 'out1']] 13>>> print(out2) 14[['A', '20180101', '5200', 'out1', 'out2'], ['B', '20180101', '800', 'out1', 'out2'], ['B', '20180112', '3500', 'out1', 'out2'], ['A', '20180105', '2000', 'out1', 'out2'], ['B', '20180107', '4000', 'out1', 'out2']] 15>>> print(out3) 16[['A', '20180101', '5200', 'out1', 'out2', 'out3'], ['B', '20180101', '800', 'out1', 'out2', 'out3'], ['B', '20180112', '3500', 'out1', 'out2', 'out3'], ['A', '20180105', '2000', 'out1', 'out2', 'out3'], ['B', '20180107', '4000', 'out1', 'out2', 'out3']] 17>>> print(out4) 18[['A', '20180101', '5200', 'out1', 'out2', 'out3', 'out4'], ['B', '20180101', '800', 'out1', 'out2', 'out3', 'out4'], ['B', '20180112', '3500', 'out1', 'out2', 'out3', 'out4'], ['A', '20180105', '2000', 'out1', 'out2', 'out3', 'out4'], ['B', '20180107', '4000', 'out1', 'out2', 'out3', 'out4']]
処理フローの途中で o= を指定することは、処理フローのデバッグに非常に効果的である。
最終結果が思わしくないものとなってしまったとき、途中経過を確認できることは、
どこに問題があるかを探るのに大いに役立つであろう。