3. mcmdによる相関ルール¶
本節では「ビールを買えばおむつも購入する」で有名な相関ルールの列挙をmcmdで行う方法について解説する 1 。 相関ルールとは、どのような商品が同時購入しやすいかについてのルールを列挙する手法である。 ルールは通常、「A=>B」のように表され、商品AとBに強い関係があることを表している。 そして、関係の強さを測る指標が色々と提案されており、特に支持度(support)、確信度(confidence)、リフト値(lift)がよく用いられる。 本節では、2つのアイテムに限定して、相関ルールを列挙する方法について紹介する。 データは、online storeのデータ・セットを用いる。 データセットの利用方法については、 オンラインストア購買データ を参照されたい。
3.1. 出力イメージ¶
表 3.1 にこの課題での出力イメージを示す。
左の2項目で相関ルール「 item1 => item2 」を示している。
freq は item1 と item2 の共起件数を表している。
共起件数とは、2つのアイテムを共に含むトランザクションの件数である。
ここで、トランザクションの定義は分析者に依存することに注意されたい。
本ケースでは、例えば、一回の注文(同じ請求番号)をトランザクションとも定義できるし、
一人の顧客をトランザクションの単位とすることも可能である。
また、一人の顧客の一ヶ月の買い物をトランザクションと定義する人もいるかも知れない。
ここでは、顧客の一日での購買をトランザクションの単位とすることにしよう。
freq1 ( freq2 )は、 item1 ( item2 ) を含むトランザクションの件数である。
total は、総トランザクション件数(総顧客数)である。
表 3.1 相関ルールの出力イメージ¶ item1
item2
freq
freq1
freq2
total
support
confidence
lift
15034
10002
2
95
49
19296
0.0001036484245
0.02105263158
8.290440387
22414
10002
1
72
49
19296
5.182421227e-05
0.01388888889
5.469387755
35961
10002
3
154
49
19296
0.0001554726368
0.01948051948
7.671349059
:
:
:
:
:
:
:
:
:
support confidence lift はルールの興味深さを定義する指標で、
相関ルール「 item1 => item2 」に関するそれぞれの定義式を以下に示す。
supportとは、 item1 と item2 の共起確率を表しており、
confidenceは、 item1 の出現を条件とした時の item2 の出現確率を表している。
liftは、 定義式では分かりにくいが、 item1 と item2 それぞれの出現確率から計算される item1 と item2 の期待共起確率に対する
実際の共起確率( support )の比である。
support と liftは、定義式よりルールに方向性はない。
すなわち \(support(item1=>item2) = support(item2=>item1)\) であり、
\(lift(item1=>item2) = lift(item2=>item1)\) である。
一方で、confidenceには方向性があり、 \(confidence(item1=>item2) \ne confidence(item2=>item1)\) である。
さてそれでは、以上9項目からなるルール一覧を作成してみよう。
3.2. ベースデータの作成¶
まず、 オンラインストア購買データ で作成したデータセット onlineRetail2.csv をカレントディレクトリにコピーしておこう。
各項目を作成するに先立ち、トランザクションデータから必要な項目、必要な行を抽出することから始めよう。
表 3.2 に今回利用するonline retailデータセットの一部を例示している。
ここでアイテムとしては StockCode 項目を使い、トランザクションとして CustomerID と date 項目を使う。
必要な項目はこれら3項目だけである。
ただし、CustomerID 項目にはnull値が含まれるため、それらの行は前もって省いておくことにする。
表 3.2 online retailデータセット¶ InvoiceNo
StockCode
Description
Quantity
UnitPrice
CustomerID
Country
date
time
536365
85123A
WHITE HANGING HEART T-LIGHT HOLDER
6
2.55
17850
United Kingdom
20101201
082600
536365
71053
WHITE METAL LANTERN
6
3.39
17850
United Kingdom
20101201
082600
536365
84406B
CREAM CUPID HEARTS COAT HANGER
8
2.75
17850
United Kingdom
20101201
082600
:
:
:
:
:
:
:
:
:
リスト 3.11 にそのスクリプトを示す。
mdelnull メソッドで CustomerID 項目がnullの行を削除し、
mcal メソッドで、 CustomerID と date を併合してトランザクションID項目 tra を作成している。
mcut で必要な項目のみ選択し、 muniq でトランザクション内の重複するアイテムを単一化している。
相関ルール分析は、一般的にアイテムを購入したか否かについてルールを列挙するもので、アイテムの数量は勘案しない。
run() の実行結果は件数が多くなるために、出力は最初の5件のみに限定している。
また、データ少し大きいため、実行時にはメッセージを表示するようにしている。
なお、ここでの run() は、後述のスクリプトに直接連結するため必要なくなる。
ここではあくまでも確認のために実行している。
1import nysol.mcmd as nm 2base=None 3base <<= nm.mdelnull(f="CustomerID,date,StockCode", i="onlineRetail2.csv") 4base <<= nm.mcal(c='cat("",$s{CustomerID},$s{date})',a="tra") 5base <<= nm.mcut(f="tra,StockCode:item") 6base <<= nm.muniq(k="tra,item") 7print(base.run(msg="on")[0:5]) 8 9# 以下画面に表示される内容 10#END# kgdelnull f=CustomerID,date,StockCode i=onlineRetail2.csv; IN=541909 OUT=406829; 2018/08/30 08:09:43; 2018/08/30 08:09:43 11#END# kgcal a=tra c=cat("",$s{CustomerID},$s{date}); IN=406829 OUT=406829; 2018/08/30 08:09:43; 2018/08/30 08:09:43 12#END# kgcut f=tra,StockCode:item; IN=406829 OUT=406829; 2018/08/30 08:09:43; 2018/08/30 08:09:43 13#END# kguniq k=tra,item; IN=406829 OUT=392940; 2018/08/30 08:09:43; 2018/08/30 08:09:43 14#END# kgload; IN=0 OUT=0; 2018/08/30 08:09:43; 2018/08/30 08:09:43 15[['1234620110118', '23166'], ['1234720101207', '20780'], ['1234720101207', '20782'], ['1234720101207', '21064'], ['1234720101207', '21171']]
3.3. トランザクション総件数¶
項目を一つずつ作成していこう。
まずは簡単なところから、トランザクションの総件数 total を計算する。
リスト 3.12 にそのスクリプトを示す。
入力は元のCSVファイルではなく、上述の base を指定していることに注意しよう。
出力の1項目目は tra 項目の値が残ってしまっているが意味はなく、
2項目目にトランザクション総件数が出力されている。
全ての項目が計算された後に、この値は結合されることになる。
なお、出力される完了メッセージを見ると、 base の内容が再実行されているが、
これは、ブロックごとに実行していっているからであり、最終的に全てを接続すれば、ダブって計算されることはない。
1total=None 2total <<= nm.mcut(f="tra", i=base) 3total <<= nm.muniq(k="tra") 4total <<= nm.mcount(a="total") 5print(total.run(msg="on")) 6 7# 以下画面に表示される内容 8#END# kgdelnull f=CustomerID,date,StockCode i=onlineRetail2.csv; IN=541909 OUT=406829; 2018/08/30 08:14:08; 2018/08/30 08:14:08 9#END# kgcal a=tra c=cat("",$s{CustomerID},$s{date}); IN=406829 OUT=406829; 2018/08/30 08:14:08; 2018/08/30 08:14:08 10#END# kgcut f=tra,StockCode:item; IN=406829 OUT=406829; 2018/08/30 08:14:08; 2018/08/30 08:14:08 11#END# kguniq k=tra,item; IN=406829 OUT=392940; 2018/08/30 08:14:09; 2018/08/30 08:14:09 12#END# kgcut f=tra; IN=392940 OUT=392940; 2018/08/30 08:14:09; 2018/08/30 08:14:09 13#END# kguniq k=tra; IN=392940 OUT=19296; 2018/08/30 08:14:09; 2018/08/30 08:14:09 14#END# kgcount a=total; IN=19296 OUT=1; 2018/08/30 08:14:09; 2018/08/30 08:14:09 15#END# kgload; IN=0 OUT=0; 2018/08/30 08:14:09; 2018/08/30 08:14:09 16[['1828720111028', '19296']]
3.4. アイテム別出現件数¶
次に、アイテム別出現件数を計算する。 リスト 3.13 にそのスクリプトを示す。 出力の2項目目にアイテムが、3項目目にその出現件数(トランザクション数)が出力されている。 ここでも結果は最初の5件のみに限定している。
1freq=None 2freq=nm.mcount(k="item", a="freq", i=base) 3print(freq.run(msg="on")[0:5]) 4 5# 以下画面に表示される内容 6# : 7#END# kgcount a=freq k=item; IN=392940 OUT=3684; 2018/08/30 08:17:45; 2018/08/30 08:17:45 8#END# kgload; IN=0 OUT=0; 2018/08/30 08:17:45; 2018/08/30 08:17:45 9[['1680520101214', '10002', '49'], ['1655120110801', '10080', '21'], ['1795020110928', '10120', '29'], ['1796720101203', '10123C', '3'], ['1311020110327', '10124A', '5']]
3.5. 共起件数¶
そして2アイテムの共起件数を求める( リスト 3.14 )。
mcombi メソッドは、トランザクション内の全アイテムから、2アイテムの順列を求め、
それら2アイテムの項目名を item1 item2 と命名している。
そしてこれら2アイテムの件数をカウントすれば、共起件数が計算できたことになる。
1cooc = None 2cooc <<= nm.mcombi(k="tra", f="item", n=2, p=True, a="item1,item2", i=base) 3cooc <<= nm.mcut(f="item1,item2") 4cooc <<= nm.mcount(k="item1,item2", a="freq") 5print(cooc.run(msg="on")[0:5]) 6 7# 以下画面に表示される内容 8# : 9#END# kgcombi -p a=item1,item2 f=item k=tra n=2; IN=392940 OUT=19267876; 2018/08/30 08:19:08; 2018/08/30 08:19:08 10#END# kgcut f=item1,item2; IN=19267876 OUT=19267876; 2018/08/30 08:19:08; 2018/08/30 08:19:08 11#END# kgcount a=freq k=item1,item2; IN=19267876 OUT=4601696; 2018/08/30 08:19:20; 2018/08/30 08:19:20 12#END# kgload; IN=0 OUT=0; 2018/08/30 08:19:20; 2018/08/30 08:19:20 13[['10002', '10120', '2'], ['10002', '10123C', '1'], ['10002', '10125', '1'], ['10002', '10133', '1'], ['10002', '10135', '3']]
3.6. 結合、そして指標の計算¶
最後に、ここまでに計算してきた結果を結合し、各種指標を計算する( リスト 3.15 )。
最後に実行される mcal で o= を指定しているので、結果はPython ListsではなくCSVファイルに書き込まれる。
1f=None 2f <<= nm.mjoin(k="item1", K="item", m=freq, f="freq:freq1", i=cooc) 3f <<= nm.mjoin(k="item2", K="item", m=freq, f="freq:freq2") 4f <<= nm.mproduct(m=total, f="total") 5f <<= nm.mcal(c="${freq}/${total}",a="support") 6f <<= nm.mcal(c='${freq}/${freq1}',a="confidence") 7f <<= nm.mcal(c='(${total}*${freq})/(${freq1}*${freq2})',a="lift", o="association.csv") 8f.run(msg="on") 9 10# 以下画面に表示される内容 11# : 12#END# kgjoin K=item f=freq:freq1 k=item1; IN=4601696 OUT=4601696; 2018/08/30 08:21:00; 2018/08/30 08:21:00 13#END# kgjoin K=item f=freq:freq2 k=item2; IN=4601696 OUT=4601696; 2018/08/30 08:21:07; 2018/08/30 08:21:07 14#END# kgproduct f=total; IN=4601696 OUT=4601696; 2018/08/30 08:21:07; 2018/08/30 08:21:07 15#END# kgcal a=support c=${freq}/${total}; IN=4601696 OUT=4601696; 2018/08/30 08:21:08; 2018/08/30 08:21:08 16#END# kgcal a=confidence c=${freq}/${freq1}; IN=4601696 OUT=4601696; 2018/08/30 08:21:08; 2018/08/30 08:21:08 17#END# kgcal a=lift c=(${total}*${freq})/(${freq1}*${freq2}) o=association.csv; IN=4601696 OUT=4601696; 2018/08/30 08:21:08; 2018/08/30 08:21:08 18'association.csv'
3.7. 全てを一つのスクリプトにまとめる¶
以上の説明では、わかりやすさのため、ブロック単位で実行してきたが、
それらを全てまとめたスクリプトを リスト 3.16 に示しておく。
ブロック単位で実行した時との違いは2つある。
1つは、 cooc ブロックと f ブロックはそのまま接続できるので、まとめて f ブロックとしている。
2つ目は、各ブロックの最後で実行していた run() はなくなり、最後の f のみrunすれば十分である。
これは、全てのブロックが何らかの形で接続され一つのストリームを形成しているからである(
もし独立のストリームが複数あれば、それぞれをrunさせる必要がある)。
全体として全てのフローが接続されている様子を見るために、スクリプトの最後で
drawModelD3 メソッドを使って処理フローを視覚化している。
図 3.1 にその結果を示している。
1#!/usr/bin/env python 2# -*- coding: utf-8 -*- 3import nysol.mcmd as nm 4 5base=None 6base <<= nm.mdelnull(f="CustomerID,date,StockCode", i="onlineRetail2.csv") 7base <<= nm.mcal(c='cat("",$s{CustomerID},$s{date})',a="tra") 8base <<= nm.mcut(f="tra,StockCode:item") 9base <<= nm.muniq(k="tra,item") 10 11total=None 12total <<= nm.mcut(f="tra", i=base) 13total <<= nm.muniq(k="tra") 14total <<= nm.mcount(a="total") 15 16freq=nm.mcount(k="item", a="freq", i=base) 17 18f = None 19f <<= nm.mcombi(k="tra", f="item", n=2, p=True, a="item1,item2", i=base) 20f <<= nm.mcut(f="item1,item2") 21f <<= nm.mcount(k="item1,item2", a="freq") 22f <<= nm.mjoin(k="item1", K="item", m=freq, f="freq:freq1") 23f <<= nm.mjoin(k="item2", K="item", m=freq, f="freq:freq2") 24f <<= nm.mproduct(m=total, f="total") 25f <<= nm.mcal(c="${freq}/${total}",a="support") 26f <<= nm.mcal(c='${freq}/${freq1}',a="confidence") 27f <<= nm.mcal(c='(${total}*${freq})/(${freq1}*${freq2})',a="lift", o="association.csv") 28f.run(msg="on") 29f.drawModelD3("association.html")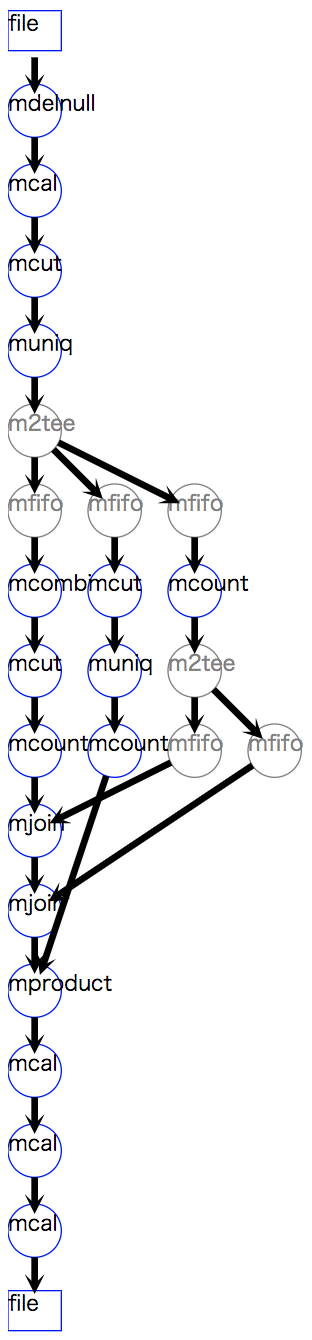
図 3.1 相関ルールを求めるスクリプトの処理フロー図¶
Footnotes