4. k-meansクラスタリング¶
本節ではonline storeのデータセットを用いて、顧客(および商品)をクラスタリングする方法について解説する。 クラスタリングには、k-means方を用いる。 ここでは統計パッケージRで利用可能なkmeans関数をPythonから呼び出すことで実現する。 以下のサンプルコードの実行は、スクリプトとしてテキストエディタで入力して実行してもよいし、 Pythonを対話モードで起動し、サンプルコードをコピペして実行していっても良い。
近年、消費者ニーズの多様化・高度化が進み、小売店サイドからすると、 自分の店にはどのような顧客が来店しくれているかを把握することは重要な経営課題となっている。 来店顧客の嗜好を知ることで、どのような顧客にどのような施策を打てばよいかがわかるし、 薄い客層の来店を促すような施策を打つこともできよう。 そこで、まずは、購買傾向の似た顧客を複数のグループに分けることを考える。 これは古くからあるクラスタリングと呼ばれる統計的手法である。 「似た」を定義するために、ここでは顧客の商品購買ベクトルを取り上げる。 online storeデータには約4000の商品が登場する。 顧客ごとに、これら4000商品の購入数量のベクトルを用意してやり、 ベクトルが似た顧客を一つのグループ(クラスタ)としてまとめてやることで、 購買傾向の似た顧客クラスタを得ることができる。 クラスタリングには様々な方法が提案されているが、ここでは k-means法 を用いる。 手法の詳細を理解することはここでの目的ではないので割愛する。
4.1. 出力イメージ¶
表 4.1 に本課題での出力イメージを示す。 単純にどの顧客がどのクラスタに属するかを表したデータである。 Rのkmeans関数は、モデルとして様々な統計値を保持している。 詳細は省くが、そこから、各クラスタに分類されたサンプル数、および各クラスタの中心ベクトルも取得する。
表 4.1 k-meansクラスタリングの出力イメージ¶ CustomerID
cluster
12347
3
12348
2
12349
2
: :
4.2. 顧客ベクトルの作成¶
まず、 オンラインストア購買データ で作成したデータセット onlineRetail2.csv をカレントディレクトリにコピーしておこう。
Rのkmeans関数のヘルプ を見ると、データは行列で与えるとあり、
行がクラスタリング対象となるサンプルで、列が変数となる。
今回のケースでは、行が顧客、列が商品ということになる。
全てのデータを使うとすると、顧客数が約4300人、商品数が約4000なので、4300×4000の行列を作成することになる。
行列の要素は、今回は簡単のために購入回数とすることにする。
実際の分析においては、購入数量を用いたり、期間あたりの数量に基準化した値を使うことになるかもしれない。
また、ある一定数量の購入の有無(0/1値)とするなども考えられるであろう。
表 4.2 に示されたonline retailデータセットから行列を作るにあたって、 まずは、 顧客(行)、商品(列)、購入回数(セル)の3項目からなる表の作成を目指そう。
表 4.2 online retailデータセット¶ InvoiceNo
StockCode
Description
Quantity
UnitPrice
CustomerID
Country
date
time
536365
85123A
WHITE HANGING HEART T-LIGHT HOLDER
6
2.55
17850
United Kingdom
20101201
082600
536365
71053
WHITE METAL LANTERN
6
3.39
17850
United Kingdom
20101201
082600
536365
84406B
CREAM CUPID HEARTS COAT HANGER
8
2.75
17850
United Kingdom
20101201
082600
:
:
:
:
:
:
:
:
:
この形式は「疎行列」と呼ばれる形式で、そのまま行列として扱えるRの関数も中にはあるが、
今回のkmeans関数は一般的な行列形式を入力データにとるので、最終的には商品を横に展開して行列形式に整形する。
顧客としては CustomerID を、商品としては StockeID を利用することにする。
購入回数の定義であるが、ある日に何度注文してもそれは1回とカウントすると定義しよう。
これらを踏まえて、疎行列の作成スクリプトは、 リスト 4.12 に示すようなものになる。
mcut で必要な項目を抜き出し、 mdelnull でnull値を含む行を削除している。
次の muniq が一日一回の購入回数定義を満たすための処理で、同じ顧客で同じ商品は日単位で単一化される。
最後に mcut で不要になった Date 項目を削除し、 mcount で顧客商品別に行数をカウントすれば出来上がりである。
実行時には run 関数に msg="on" を指定することで、各メソッドの終了メッセージを画面に表示させている。
また結果は、最初の5行のみを表示させている( [0:5] )。
出力結果の各行の3つの値は、左から顧客、商品、購入回数である。
1import nysol.mcmd as nm 2f=None 3f <<= nm.mcut(f="CustomerID,StockCode,Date",i="onlineRetail2.csv") 4f <<= nm.mdelnull(f="*") 5f <<= nm.muniq(k="CustomerID,StockCode,Date") 6f <<= nm.mcut(f="Date",r=True) 7f <<= nm.mcount(k="CustomerID,StockCode",a="freq") 8print(f.run(msg="on")[0:5]) 9# 以下画面に表示される内容 10# #END# kgcut f=CustomerID,StockCode,Date i=onlineRetail2.csv; IN=541909 OUT=541909; 2018/09/08 08:12:23; 2018/09/08 08:12:23 11# #END# kgdelnull f=*; IN=541909 OUT=406829; 2018/09/08 08:12:23; 2018/09/08 08:12:23 12# #END# kguniq k=CustomerID,StockCode,Date; IN=406829 OUT=392940; 2018/09/08 08:12:24; 2018/09/08 08:12:24 13# #END# kgcut -r f=Date; IN=392940 OUT=392940; 2018/09/08 08:12:24; 2018/09/08 08:12:24 14# #END# kgcount a=freq k=CustomerID,StockCode; IN=392940 OUT=267615; 2018/09/08 08:12:24; 2018/09/08 08:12:24 15# #END# kgload; IN=0 OUT=0; 2018/09/08 08:12:24; 2018/09/08 08:12:24 16# [['12346', '23166', '1'], ['12347', '16008', '1'], ['12347', '17021', '1'], ['12347', '20665', '1'], ['12347', '20719', '4']]
そして次に、疎行列を一般の行列形式に変換するのであるが、
いくつかのアプローチがあり、大きくは、1) mcmdメソッドで行う、2)Pythonコードを書く、3)R内でやる、が考えられる。
基本的には得意な方法で実現すれば良いが、ここでは1)の方法を紹介する(mcmdのチュートリアルなので)。
リスト 4.13 がそのコードで、 m2cross と mnullto の2つのメソッドで実現できる。
m2cross はクロス集計用のメソッドで、 k= で指定された項目を行に、 s= で指定された項目を列に、
そして f= で指定された項目をセルにフォーマットを変換してくれる。
値の無いセルはnull値のままなので、次の mnullto でnull値を0に変換している。
ここで、 リスト 4.13 で作成された行列は 4000×4300の大きな行列である。 顧客ベクトルのサイズは4300にもなり、もしうまくクラスタリングできたとしても、その特徴を見るのに 4300の商品を眺めるのはなかなか困難なことである。 そこで、ベクトルのサイズを小さくしてみよう。 ここでは簡単のために、全体で一定回数以上購入されている商品のみを対象とする。 リスト 4.14 にここまでの全てのコード合わせて示している。 わかりやすさのため、オブジェクトの変数名は上述のものから変更している。
疎行列を求める処理オブジェクト base の出力結果を使って、
商品の総購入回数を freq オブジェクトにて計算し、 一定以上(ここでは1000)の購入がある商品のみに絞っている。
そして、次の matrix ブロックにて、 mcommon を用いて疎行列からそれらの商品を選択している。
商品の選択のために、元データ onlineRetail2.csv から再計算しても良いが、疎行列の計算で
すでに目的とする商品の総購入回数の前段階まで計算が終わっているので、そのデータを使いまわしている。
もし元データから再計算させると同じような処理内容のオブジェクトが増え、バグの温床になってしまう。
そして最後に、疎行列を行列に変換し、CSVファイル custVectors.csv に書き出している。
ここでも最終結果をリスト形式で保持し、そのままRに渡してやることもできるが、ファイルに出力することで確認も可能になり、
なによりpythonとRとの境界線がここにできてわかりやすい。
では、次にそのファイルをRに読み込ませてk-meansクラスタリングを行おう。
1import nysol.mcmd as nm 2base=None 3base <<= nm.mcut(f="CustomerID,StockCode,Date",i="onlineRetail2.csv") 4base <<= nm.mdelnull(f="*") 5base <<= nm.muniq(k="CustomerID,StockCode,Date") 6base <<= nm.mcut(f="Date",r=True) 7base <<= nm.mcount(k="CustomerID,StockCode",a="freq") 8 9freq=None 10freq <<= nm.msum(k="StockCode", f="freq", i=base) 11freq <<= nm.mselnum(f="freq",c="[1000,]") 12 13matrix=None 14matrix <<= nm.mcommon(k="StockCode",m=freq,i=base) 15matrix <<= nm.m2cross(k="CustomerID", s="StockCode", f="freq") 16matrix <<= nm.mnullto(f="*", v=0, o="custVectors.csv") 17matrix.run(msg="on")
4.3. pyperモジュール¶
pyperモジュールは、PythonからバックグラウンドでRを起動し、
パイプ(プロセス間通信)によってRに処理命令を送ることを可能にするモジュールである。
実際の開発では、Rを起動して、上で作成した行列ファイルを直接読み込み、
試行錯誤しながら実行手順を作り上げていく方が、特にデバッグ面において効率的かもしれない。
Rの詳細を紹介するのが目的ではないので、以下のサンプルコードでは直接pyperを用いてコーディングしている。
リスト 4.15 にpyperによりRを実行するコードを示す。
このコードにより、最終的に、最初に示した最終出力の顧客-cluser表がCSV( r_cluster.csv )で出力される。
1r = pyper.R() # Rの起動 2r("d=read.csv('custVectors.csv')") # 顧客-商品行列をデータフレームとして読み込み変数dにセット 3r("rownames(d)=d[,1]") # 顧客IDである1列目(d[,1])を行の名前にする 4r("d=d[,-1]") # 顧客ID列は削除する 5r("m=kmeans(d,10)") # k-meansの実行:クラスタ数は10に設定,結果をRの変数mに代入 6r("md=as.data.frame(m$cluster)") # k-meansの結果(m)に格納された顧客-クラスタ番号ベクトルをデータフレーム形式に変更する 7r("write.table(md,file='r_cluster.csv',col.names=FALSE,sep=',')") # 項目名ヘッダーを除いてデータ本体のみCSVに書き出す 8 9m=r.get("m") # モデルオブジェクトを取得しPythonの変数mに代入 10print(m) # その内容の表示 11# 以下、print(m)の内容 => Pythonの辞書型で返ってくる 12# {'cluster': array([10, 3, 10, ..., 3, 10, 1]), 'centers': array([[6.70212766e+00, 5.29787234e+00, 1.82978723e+00, 1.27659574e+00, 13# 5.06382979e+00, 9.36170213e-01, 1.06382979e+00, 4.36170213e+00,..., 14# 1.64725458e-01, 1.69717138e-01, 1.73044925e-01]]), 'totss': 80815.9532554257, 'withinss': array([6010.68085106, 8038.72727273, 4885.00984103, 2527.19148936, 15# 2833.63364486, 5287.32642487, 3302.43939394, 4524.12244898, 16# 2684.528 , 2879.85357737]), 'tot.withinss': 42973.5129442027, 'betweenss': 37842.440311223, 'size': array([ 47, 11, 1321, 47, 535, 193, 66, 49, 125, 601]), 'iter': 5, 'ifault': 0} 17 18print(m["cluster"]) # cluster変数を表示 19# [2 4 4 ... 4 4 8] 20 21centers = r.get("m$centers") # 各クラスタの中心ベクトルの表示 22print(centers) 23# [[4.35897436e-01 2.43589744e-01 6.02564103e-01 7.05128205e-01 24# 3.20512821e-01 1.46153846e+00 1.11538462e+00 3.71794872e-01 25# : 26# 2.32142857e-01 2.58928571e-01 2.23214286e-02]] 27 28sizes = r.get("m$size") # 各クラスタのサイズ(分類されたサンプル数)の表示 29print(sizes) 30# [ 78 101 69 1787 165 267 2 28 50 448]
pyperでは、 pyper.R() にてバックグラウンドでRを起動し、
r(Rへの命令文字列) の形式で、Rでの処理を実行する。
Rでの結果を直接取得するには、 r.get(オブジェクト名) メソッドを使う。
最終結果はCSVファイルに出力している。
各行の意味はコメントして示している。
途中、モデルの内容をPythonの辞書として取得しているが、その内容については、kmeansのマニュアル等を参照して理解する。
目的の顧客-クラスタ対応表は m$cluster 変数に格納されている。
ただし、Pythonに持ってきたときには単純なクラスタ番号リストになっており、オリジナルで保持していた顧客IDのラベルが消えてしまっている。
そこで、Rの中でデータフレームに変換し、それをCSVファイルに出力している。
このような細かな対応は、やはりRインタプリタを起動して直接行う方が効率がよいであろう。
4.4. 全体のスクリプト¶
最後に、上述の処理をまとめたスクリプトを リスト 4.16 に示しておく。 途中、顧客-商品行列を作成する処理フローを視覚化するコードを入れている(22行目)。 図 4.6 はその内容である。 また、最後に項目名を追加して顧客-クラスタ表を整形しCSVに出力するコードも追加している(39-41行目)。
1#!/usr/bin/env python 2# -*- coding: utf-8 -*- 3import nysol.mcmd as nm 4import pyper 5 6base=None 7base <<= nm.mcut(f="CustomerID,StockCode,date",i="onlineRetail2.csv") 8base <<= nm.mdelnull(f="*") 9base <<= nm.muniq(k="CustomerID,StockCode,date") 10base <<= nm.mcut(f="date",r=True) 11base <<= nm.mcount(k="CustomerID,StockCode",a="freq") 12 13freq=None 14freq <<= nm.msum(k="StockCode", f="freq", i=base) 15freq <<= nm.mselnum(f="freq",c="[1000,]") 16 17matrix=None 18matrix <<= nm.mcommon(k="StockCode",m=freq,i=base) 19matrix <<= nm.m2cross(k="CustomerID", s="StockCode", f="freq") 20matrix <<= nm.mnullto(f="*", v=0, o="custVectors.csv") 21matrix.run(msg="on") 22matrix.drawModelD3("kmeans.html") 23 24r = pyper.R() 25r("d=read.csv('custVectors.csv')") 26r("rownames(d)=d[,1]") 27r("d=d[,-1]") 28r("m=kmeans(d,10)") 29r("md=as.data.frame(m$cluster)") 30r("write.table(md,file='r_cluster.csv',col.names=FALSE,sep=',')") 31m = r.get("m") 32print(m) 33print(m["cluster"]) 34centers = r.get("m$centers") 35print(centers) 36sizes = r.get("m$size") 37print(sizes) 38 39f=None 40f <<= nm.mcut(nfni=True,f="0:CustomerID,1:cluster",i="r_cluster.csv",o="cust_cluster.csv") 41f.run(msg="on")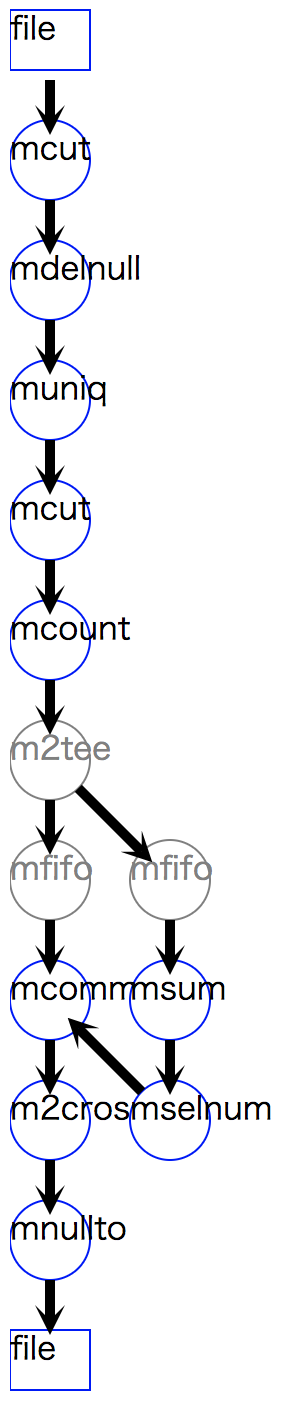
図 4.6 k-meansクラスタリングの入力データ(顧客-商品)行列を作成するスクリプトのフロー図¶