| MCMD2 |
3.5 mbest 指定行の選択
指定した行番号の行を選択する。 行番号は0から始まることに注意する(項目名行は除いて、データ本体の先頭行が0行目)。 行番号はfrom=とto=(もしくはsize=)で指定する。
書式
mbest s= [R=] [from=] [to=|size=] [k=] [u=] [-r] [i=] [o=] [-assert_diffSize] [-assert_nullkey] [-nfn] [-nfno] [-x] [-q] [tmpPath=] [--help] [--helpl] [--version]
パラメータ
s= |
ここで指定した項目(複数項目指定可)で並べ替えられた後、指定した行が選択される。 |
-qオプションを指定しないとき、s=パラメータは必須。 |
|
from= |
選択する開始行番号(0以上の整数)【デフォルト値:0】 |
to= |
選択する終了行番号(0以上の整数)【デフォルト値:0】 |
「from=の値」 |
|
size= |
選択する行数【デフォルト値:1】 |
to=とsize=の両方を同時に指定することはできない。 |
|
k= |
指定列の項目(複数項目指定可)が同じ値の行ごとに、from=,to=,size=で指定した行番号の行を選択する。 |
-x,-nfnオプション使用時は、項目番号(0〜)で指定可能。 |
|
u= |
不一致データ出力ファイル名 |
指定の条件に一致しない行を出力するファイル名。 |
|
-r |
条件反転 |
from=,to=(size=)パラメータで指定した行番号以外の行を選択する。 |
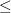 「to=の値」でなければならない。
「to=の値」でなければならない。利用例
例1: 基本例
この例では、「数量」と「金額」項目値の大きい順(降順)に並べ替えている。 from=,to=,size=を指定しなければ先頭行(0行目)のみ選択する
$ more dat1.csv 顧客,数量,金額 A,20,5200 B,18,4000 C,15,3500 D,10,2000 E,3,800 $ mbest s=数量%nr,金額%nr i=dat1.csv o=rsl1.csv #END# kgbest i=dat1.csv o=rsl1.csv s=数量%nr,金額%nr $ more rsl1.csv 顧客,数量%0nr,金額%1nr A,20,5200
例2: 基本例2
「顧客」で並べ替えた後、先頭行(0行目)から3行選択する
$ mbest s=顧客 from=0 size=3 i=dat1.csv o=rsl2.csv #END# kgbest from=0 i=dat1.csv o=rsl2.csv s=顧客 size=3 $ more rsl2.csv 顧客%0,数量,金額 A,20,5200 B,18,4000 C,15,3500
例3: 基本例3
並べ替えを行わず(もとのレコード順序を維持したまま)、0行目から1行目まで選択する
$ mbest -q from=0 to=1 i=dat1.csv o=rsl3.csv #END# kgbest -q from=0 i=dat1.csv o=rsl3.csv to=1 $ more rsl3.csv 顧客,数量,金額 A,20,5200 B,18,4000
例4: 条件反転
顧客の初回来店日以外の行を選択する。 初回来店日はfvd.csvというファイルに出力する。
$ more dat2.csv 顧客,日付,金額 A,20081201,10 A,20081207,20 A,20081213,30 B,20081002,40 B,20081209,50 $ mbest s=顧客,日付 k=顧客 -r u=fvd.csv i=dat2.csv o=rsl4.csv #END# kgbest -r i=dat2.csv k=顧客 o=rsl4.csv s=顧客,日付 u=fvd.csv $ more rsl4.csv 顧客,日付,金額 A,20081207,20 A,20081213,30 B,20081209,50 $ more fvd.csv 顧客,日付,金額 A,20081201,10 B,20081002,40
関連コマンド
msel : line()関数を使えば、同じようなことができる。
muniq : 単純にキー項目を単一化したいだけならこれ。
mselnum : 数値範囲によって行選択ができる。
| MCMD2 |