| MCMD2 |
2.9 パラメータ指定
Mコマンドで使われるパラメータの書式は、一般的なUNIXコマンドのものとは少し異なる。 値を伴うパラメータは「キーワード=値」のように、キーワードと値をイコール記号で区切って指定する。 またオプション型のパラメータは、「-キーワード」のように、先頭にマイナス記号一つを付ける。
またMコマンドで使われるパラメータには、概ね共通した意味で用いられるものが多い。 以下では、それらのパラメータについて解説する。 ただし、コマンドによっては全く異なる意味として実装されているケースもあるので注意されたい。
キーワード |
意味 |
入力ファイル名 |
|
出力ファイル名 |
|
入出力項目名 |
|
キー項目名 |
|
並べ替え項目名 |
|
追加項目名 |
|
項目名行のないCSV |
|
項目名行を出力しない |
|
項目番号による指定 |
|
自動並べ替えの無効化 |
|
入力、出力件数比較を行う |
|
キー項目にNULL値が含まれているかどうかのチェックを行う |
|
入力項目のf=またはvf=で指定された項目のNULL値チェックを行う |
|
出力項目のNULL値チェックを行う |
|
有効桁数 |
|
作業ファイル格納パス名 |
|
ベクトル型データの区切り文字 |
|
バッファの数 |
|
--help |
英語ヘルプを表示する |
--helpl |
日本語ヘルプを表示する |
2.9.1 i= 入力ファイル名
入力ファイル名を指定する。 多くのコマンドでは単一のファイルのみ指定可能で、例外としてmcatコマンドは複数のファイル名をカンマで区切って指定できる。 また入力データを必要としないコマンド、例えば、mnewrandやmnewnumberなどもある。
このパラメータが省略された時には標準入力からデータを読み込む。 この機能があるために、パイプラインによる接続が可能となる。 例えば、以下の例では、msumでi=を指定していないが、 これはmsortfの結果がパイプラインを介して標準入力としてデータが入力されるためである。
$ msortf f=a i=dat.csv | msum k=a f=b o=rsl.csv
また、上記と同様の処理を行うに当たって、気づきにくい間違いを以下に示そう。 上記との違いはmsumにi=パラメータが指定されている点である。 この例は残念ながらエラーとはならない。 msortf の結果は標準出力に出力され、msumはdat.csvから読み込んで処理を行う。 よって、msortfを実行している意味が全くなくなっており、得られる結果も異なったものとなるであろう。
$ msortf f=a i=dat.csv | msum k=a f=b i=dat.csv o=rsl.csv
利用例
例1: 基本例
dat1.csvを入力データとしてmcutは実行される。
$ more dat1.csv 顧客,数量,金額 A,1,10 A,2,20 $ mcut f=顧客,金額 i=dat1.csv o=rsl1.csv #END# kgcut f=顧客,金額 i=dat1.csv o=rsl1.csv $ more rsl1.csv 顧客,金額 A,10 A,20
例2: 出力項目名の指定
標準入力をリダイレクト("<"記号)して読み込む。
$ mcut f=顧客,金額 o=rsl2.csv <dat1.csv #END# kgcut f=顧客,金額 o=rsl2.csv $ more rsl2.csv 顧客,金額 A,10 A,20
対応コマンド
mnewnumber,mnewrandなど一部のコマンドを除いて全てのコマンドで利用できる。
2.9.2 o= 出力ファイル名
出力ファイル名を指定する。 単一のファイルのみ指定可能である。 ただし、例外として、mteeコマンドは複数の出力ファイルを指定でき、 また出力データを必要としないコマンド、例えば、msepなどもある。
このパラメータが省略された時には標準出力にデータを書き込む。 この機能があるために、パイプラインによる接続が可能となる。 例えば、以下の例では、msortfでo=を指定していないが、 これはmsortfの結果が標準出力を通じてパイプラインに出力されるためである。
$ msortf f=a i=dat.csv | msum k=a f=b o=rsl.csv
また、上記の似たような処理ではあるが、以下に示した例はうまく動作しない。 上記との違いはmsortfにo=パラメータが指定されている点である。 msortfの結果はtmp.csvに出力されるが、標準出力に出力するデータがなく、 パイプ接続されたmsumはいつまでも入力データが来るのを待つこととなり、一見動いているように見えて、いつまでも終了しない。
$ msortf f=a i=dat.csv o=tmp.csv | msum k=a f=b o=rsl.csv
少し複雑な例であるが、上記の例は以下のようにmteeコマンドを利用することでうまく動作するようになる。
$ msortf f=a i=dat.csv | mtee o=tmp.csv | msum k=a f=b o=rsl.csv
mteeコマンドは、標準入力をo=で指定されたファイルおよび標準出力に書き出す。 結果として、msortfの結果はtmp.csvに書きこまれ、msumもmteeよりパイプラインを通じてデータ供給を受け、 最終結果をrsl.csvに書き出す。
利用例
例1: 基本例
mcutの実行結果はo=で指定したrsl1.csvに出力される。
$ more dat1.csv 顧客,数量,金額 A,1,10 A,2,20 $ mcut f=顧客,金額 i=dat1.csv o=rsl1.csv #END# kgcut f=顧客,金額 i=dat1.csv o=rsl1.csv $ more rsl1.csv 顧客,金額 A,10 A,20
例2: リダイレクト
標準出力をリダイレクト(">"記号)して書き込む。
$ mcut f=顧客,金額 i=dat1.csv >rsl2.csv #END# kgcut f=顧客,金額 i=dat1.csv $ more rsl2.csv 顧客,金額 A,10 A,20
対応コマンド
sepなど一部のコマンドを除いて全てのコマンドで利用できる。
2.9.3 f= 入出力項目名
処理対象となる入力項目名の指定をおこなう。 例えば、mcutにおいては「選択される項目名」、maggにおいては「集計される項目名」、mjoinにおいては「結合される項目名」を指定する。 また複数の項目名は、f=a,b,cのようにカンマで区切って指定する。
さらに、指定された項目毎に出力項目名を指定できるコマンドもある。 出力項目名は、f=a:A,b:Bのように、入力項目名の後にコロンで区切って指定する。 出力項目名が省略されたときは、入力項目名と同じ項目名が利用される。
利用例
例1: 基本例
項目val1とval2を切り出す。
$ more dat1.csv id,val1,val2 A,1,2 B,2,3 C,3,4 $ mcut f=val1,val2 i=dat1.csv o=rsl1.csv #END# kgcut f=val1,val2 i=dat1.csv o=rsl1.csv $ more rsl1.csv val1,val2 1,2 2,3 3,4
例2: 出力項目名の指定
val1,val2を集計し、sum1,sum2という項目名で出力する。
$ msum f=val1:sum1,val2:sum2 i=dat1.csv o=rsl2.csv #END# kgsum f=val1:sum1,val2:sum2 i=dat1.csv o=rsl2.csv $ more rsl2.csv id,sum1,sum2 C,6,9
対応コマンド
2.9.4 k= キー項目名
キー項目を指定する(複数項目指定可)。 キー項目とは、集計の単位として指定したり、 またファイルの結合時に2ファイル間の共通項目として指定したりする項目である。
たとえばmsumコマンドでは、同一キーごとに合計処理を実施する(集計キーブレイク処理)。 またmjoinコマンドでは、2つのデータファイルについて、キー項目の大小を見比べて 結合処理を実施する(結合キーブレイク処理)。
k=パラメータが指定されたとき、コマンドはまずその項目を文字列昇順で並べ替えた上で、 それぞれの処理を実行する(ただし、mhashsumコマンドのような例外もある)。
なおキーブレイク処理の詳細は、キーブレイク処理を参照のこと。 項目の並べ替えが頻繁に発生するとパフォーマンスの低下を招くため、 キーブレイク処理の内容と必要性を理解した上で、並べ替えの回数を少なくする スクリプトを記述することが望ましい。
利用例
例1: 基本例
id項目別にval項目の値を合計する。
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ msum i=dat1.csv k=id f=val o=rsl1.csv #END# kgsum f=val i=dat1.csv k=id o=rsl1.csv $ more rsl1.csv id%0,val A,3 B,6
例2: 結合処理
dat1.csvのidを結合キーに、ref1.csvのname項目を結合する。
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ more ref1.csv id,name A,nysol B,mcmd $ mjoin i=dat1.csv k=id m=ref1.csv f=name o=rsl4.csv #END# kgjoin f=name i=dat1.csv k=id m=ref1.csv o=rsl4.csv $ more rsl4.csv id%0,val,name A,1,nysol A,2,nysol B,1,mcmd B,2,mcmd B,3,mcmd
対応コマンド
msum, mslide, mjoin, mrjoin, mcommonなど
2.9.5 s= 並べ替え項目名
並べ替え項目名を指定する(複数指定可)。
maccumなどいくつかのコマンドは、行(レコード)の順序が処理結果に影響を与える。 s=パラメータを指定すると、コマンドはあらかじめその項目で行を並べ替えたのち、 それぞれの処理を実行する。
項目の並べ替え方法(並び順)は、数値/文字列、昇順/降順の組み合わせで4通り指定できる。 指定方法は、項目名のあと%に続けてnとrを以下の通り組み合わせる。
文字列昇順:項目名(%指定なし)、文字列逆順:f=項目名%r、数値昇順:f=項目名%n、数値降順:f=項目名%nr。
利用例
例1: 基本例
id項目で並べ替えた後、val項目の累計を計算する。
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ maccum s=id k=id f=val:val_accum i=dat1.csv o=rsl1.csv #END# kgaccum f=val:val_accum i=dat1.csv k=id o=rsl1.csv s=id $ more rsl1.csv id,val,val_accum A,1,1 A,2,3 B,1,1 B,2,3 B,3,6
例2: 並べ替え方法を指定する
val項目を数値降順で並べ替えた後、val項目の累計を計算する。
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ maccum s=id,val%nr k=id f=val:val_accum i=dat1.csv o=rsl1.csv #END# kgaccum f=val:val_accum i=dat1.csv k=id o=rsl1.csv s=id,val%nr $ more rsl1.csv id,val,val_accum A,2,2 A,1,3 B,3,3 B,2,5 B,1,6
対応コマンド
maccum, mbest, mmvavg, mnumber, mslideなど
2.9.6 a= 追加項目名
新たに項目を追加するようなコマンドにおいて、その項目名を指定する。 多くのコマンドは、追加する項目は一つであるため、ここで指定する項目名も一つであることが多い。 中には、mcombiコマンドのように複数の項目を出力するものもあるが、その際はカンマで区切って複数の項目名を指定する。
利用例
例1: 基本例
精算日という新しい項目を追加する。
$ more dat1.csv id A B C $ msetstr v=20070101 a=精算日 i=dat1.csv o=rsl1.csv #END# kgsetstr a=精算日 i=dat1.csv o=rsl1.csv v=20070101 $ more rsl1.csv id,精算日 A,20070101 B,20070101 C,20070101
例2: 複数項目を追加
id項目のデータA,B,Cの2つの組合わせを2つの項目(id1,id2)として出力する。
$ mcombi f=id n=2 a=id1,id2 i=dat1.csv o=rsl2.csv #END# kgcombi a=id1,id2 f=id i=dat1.csv n=2 o=rsl2.csv $ more rsl2.csv id,id1,id2 C,A,B C,A,C C,B,C
対応コマンド
mcal, mcombi, mrand, msetstrなど
2.9.7 -nfn 項目名行のないCSV(No Field Namesの略)
このオプションを指定すると入力データの1行目を項目名行とみなさない。 主に1行目に項目名がないデータの場合に利用される。 このフラグを指定すると項目指定のときに項目名は利用できないので項目番号指定をすることになる。 項目番号は0から始まる整数で指定することに注意する。 -nfnオプションを指定すると、出力ファイルにも項目名は出力されない。
利用例
例1: 基本例
0番目と2番目の項目を切り出す。
$ more dat1.csv A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ mcut -nfn f=0,2 i=dat1.csv o=rsl1.csv #END# kgcut -nfn f=0,2 i=dat1.csv o=rsl1.csv $ more rsl1.csv A,10 A,20 B,15 B,10 B,20
対応コマンド
mchkcsv以外全てのコマンドで利用できる。
2.9.8 -nfno 項目名行を出力しない(No Field Names for Outputの略)
このオプションを指定すると出力データに項目名行を出力しない。 -nfnとは違い、i=やm=で指定される入力データは項目名行を伴うデータを前提とする。
利用例
例1: 基本例
数量と金額項目を切りだすが、出力データには項目名行は出力されない。
$ more dat1.csv 顧客,数量,金額 A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ mcut -nfno f=数量,金額 i=dat1.csv o=rsl1.csv #END# kgcut -nfno f=数量,金額 i=dat1.csv o=rsl1.csv $ more rsl1.csv 1,10 2,20 1,15 3,10 1,20
対応コマンド
mchkcsv以外全てのコマンドで利用できる。
2.9.9 -x 項目番号による指定
項目名行を伴う入力データに対して項目番号によって項目を指定したい場合にこのオプションを用いる。 コロンで区切って出力項目名を指定することも可能である。
利用例
例1: 基本例
0番目項目を集計キーとして1番目と2番目の項目を合計する。
$ more dat1.csv 顧客,数量,金額 A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ msum -x k=0 f=1,2 i=dat1.csv o=rsl1.csv #END# kgsum -x f=1,2 i=dat1.csv k=0 o=rsl1.csv $ more rsl1.csv 顧客%0,数量,金額 A,3,30 B,5,45
例2: 出力項目名も利用可能
1番目と2番目の項目は、a,bという名前で出力する。
$ msum -x k=0 f=1:a,2:b i=dat1.csv o=rsl2.csv #END# kgsum -x f=1:a,2:b i=dat1.csv k=0 o=rsl2.csv $ more rsl2.csv 顧客%0,a,b A,3,30 B,5,45
例3: -nfnではうまくいかない
-nfnは、最初の行をデータ行としてみなすので、「数量」「金額」というデータを合計しようとしてしまい、うまくいかない。 -xは、あくまでも最初の行は項目名行とみなす点が-nfnと異なる。
$ msum -nfn k=0 f=1,2 i=dat1.csv o=rsl3.csv #END# kgsum -nfn f=1,2 i=dat1.csv k=0 o=rsl3.csv $ more rsl3.csv 顧客,0,0 A,3,30 B,5,45
対応コマンド
mchkcsv以外全てのコマンドで利用できる。
2.9.10 -q 自動並べ替えの無効化
k=パラメータで指定した項目による自動並べ替えを無効にしたい場合にこのオプションを用いる。 s=オプションも省略可能となり、各コマンドはMCMD Ver. 1.0と同等の動作をするようになる。
利用例
例1: 基本例
id項目の値が連続しているときの累計を求める。-qオプションを指定することで、 事前にk=パラメータで指定した項目で並べ替える機能を無効化している。
$ more dat1.csv id,val A,1 B,1 B,2 A,2 B,3 $ maccum -q k=id f=val:val_accum i=dat1.csv o=rsl1.csv #END# kgaccum -q f=val:val_accum i=dat1.csv k=id o=rsl1.csv $ more rsl1.csv id,val,val_accum A,1,1 B,1,1 B,2,3 A,2,2 B,3,3
対応コマンド
k=パラメータを持つすべてのコマンドで利用できる。
2.9.11 -assert_diffSize 入力、出力件数比較を行う
このパラメータを指定すると入力ファイルと出力ファイルの件数の比較を行い、 入力ファイルと出力ファイルの件数が異なる場合に、「#WARNING# ; the number of lines is different」というメッセージを表示する。
利用例
(基本例)
例えば、mjoin(参照ファイルの項目結合)コマンドを利用する際に、入力ファイルのキー項目(k=パラメータで指定する項目)と参照ファイルのキー項目(K=パラメータで指定する項目)が完全に一致しているかどうかを確認したい場合を想定する。mjoinコマンドでNULL値を出力する-n、-Nパラメータを指定しない場合は、入力ファイルと参照ファイルで共通のキー項目のみが結合され、一致しないキー項目の値は除外される為、入力データと出力データの件数が異なる。その際、-assert_diffSizeパラメータを指定しておくと、入力ファイルと出力ファイルの件数の比較を行い、入力ファイルと出力ファイルの件数が異なる場合に「#WARNING# ; the number of lines is different」というメッセージを表示するので入力ファイルと参照ファイルのキー項目が完全に一致していないことを確認することができる。
$ more dat1.csv item,date,price A,20081201,100 A,20081213,98 B,20081002,400 B,20081209,450 C,20081201,100 $ more ref1.csv item,cost A,50 B,300 E,200 $ mjoin k=item f=cost m=ref1.csv -assert_diffSize i=dat1.csv o=rsl1.csv #WARNING# ; the number of lines is different #END# kgjoin -assert_diffSize f=cost i=dat1.csv k=item m=ref1.csv o=rsl1.csv; IN=5 OUT=4 $ more rsl1.csv item%0,date,price,cost A,20081201,100,50 A,20081213,98,50 B,20081002,400,300 B,20081209,450,300
対応コマンド
marff2csv, mchkcsv, mcsv2arff, mnewnumber, mnewrand, mnewstr, msep, msep2, mtee, mxml2csv
上記以外の全てのコマンドで利用できる。
2.9.12 -assert_nullkey キー項目にNULL値が含まれているかどうかのチェックを行う
このパラメータを指定すると、キー項目(k=またはK=パラメータで指定する項目)にNULL値が含まれているかどうかのチェックを行い、NULL値が含まれていた場合に、「#WARNING# ; exist NULL in key filed」というメッセージを表示する。
利用例
(基本例)
例えば、msum(項目値の合計)コマンドを例にあげる。k=パラメータで指定した項目の値が同じ行に対して、f=パラメータで指定した集計項目の項目値を合計することを想定した場合、データによっては、k=パラメータで指定したキー項目の値にNULL値が含まれている場合がある。-assert_nullkeyパラメータを指定すると、キー項目の値にNULL値が含まれているかどうかのチェックを行い、NULL値が含まれていた場合に、「#WARNING# ; exist NULL in key filed」というメッセージを表示するのでキー項目にNULL値が含まれていたかどうかを確認することができる。
$ more dat1.csv 顧客,数量,金額 A,1,10 ,1,10 B,1,15 A,2,20 B,3,10 B,1,20 $ msum k=顧客 f=数量:数量合計,金額:金額合計 -assert_nullkey i=dat1.csv o=rsl1.csv #WARNING# ; exist NULL in key filed #END# kgsum -assert_nullkey f=数量:数量合計,金額:金額合計 i=dat1.csv k=顧客 o=rsl1.csv $ more rsl1.csv 顧客%0,数量合計,金額合計 ,1,10 A,3,30 B,5,45
対応コマンド
maccum, mavg, mbest, mbucket, mcal, mcommon, mcount, mcross, mdelnull, mhashavg, mhashsum, mjoin, mkeybreak, mmbucket, mmvavg, mmvsim, mstats, mnjoin, mnormalize, mnrcommon, mnrjoin, mnumber, mpadding, mrand, mrjoin, mselnum, mselrand, mselstr, msep2, mshare, msim, mslide, mstats, msum, msummary, mtra, muniq, mwindow
上記のコマンドで利用できる。
2.9.13 -assert_nullin 入力項目のf=またはvf=で指定された項目のNULL値チェックを行う
このパラメータを指定すると、f=またはvf=で指定された入力項目にNULL値が含まれているかどうかのチェックを行い、NULL値が含まれていた場合に、「#WARNING# ; exist NULL in input data」というメッセージを表示する。
利用例
(基本例)
例えば、maccum(累積計算)コマンドを利用することを想定した場合、maccumコマンドはf=パラメータで指定した項目の値がNULL値である場合は無視して計算を行う。f=パラメータで指定した項目の値にNULL値が含まれているかどうかを確認したい場合、-assert_nullinパラメータを指定すると、f=パラメータで指定された入力項目の値にNULL値が含まれているかどうかのチェックを行い、NULL値が含まれていた場合に、「#WARNING# ; exist NULL in input data」というメッセージを表示するのでNULL値が含まれていたかどうかを確認することができる。
$ more dat1.csv 顧客,数量,金額 A,1, A,2,20 B,1,15 B,3,10 B,,20 $ maccum s=顧客 f=数量:数量累計,金額:金額累計 -assert_nullin i=dat1.csv o=rsl1.csv #WARNING# ; exist NULL in input data #END# kgaccum -assert_nullin f=数量:数量累計,金額:金額累計 i=dat1.csv o=rsl1.csv s=顧客 $ more rsl1.csv 顧客%0,数量,金額,数量累計,金額累計 A,1,,1, A,2,20,3,20 B,1,15,4,35 B,3,10,7,45 B,,20,,65
対応コマンド
marff2csv, mbest, mbucket, mchkcsv, mcommon, mcount, mdelnull, mfldname, mkeybreak, mnewnumber, mnewrand, mnewstr, mnrcommon, mnullto, mnumber, mrand, msel, mselrand, msep2, msetstr, msortf, mtee, muniq, mwindow, mxml2csv
上記のコマンドを除いて全てのコマンドで利用できる。
2.9.14 -assert_nullout 出力項目のNULL値チェックを行う
このパラメータを指定すると、出力項目にNULL値が含まれているかどうかのチェックを行い、NULL値が含まれていた場合に、「#WARNING# ; exist NULL in output data」というメッセージを表示する。 ただし、計算項目など、入力データがそのまま出力されるものについてはチェックを行わない。
利用例
(基本例)
例えば、mslide(行ずらし)コマンドを例にあげる。k=パラメータで指定した項目単位に、f=パラメータで指定した項目の値を、t=パラメータで指定した行数ずらすことを想定した場合、データによっては、f=パラメータで指定した項目の行数よりも、t=パラメータで指定したずらす回数の方が多いケースがある。そのような処理をする場合に-nパラメータを指定することで、次(前)の行がなくてもNULL値を入れて出力することがある。出力項目にNULL値が含まれているかどうかを確認したい場合、-assert_nulloutパラメータを指定すると、出力項目の値にNULL値が含まれているかどうかのチェックを行い、NULL値が含まれていた場合に、「#WARNING# ; exist NULL in output data」というメッセージを表示するので出力項目にNULL値が含まれていたかどうかを確認することができる。
下記の例では出力項目のsyo_1,syo_2コマンドの値にNULL値が含まれているかどうかのチェックを行い、含まれている為「#WARNING# ; exist NULL in output data」が出力されている。
$ more dat1.csv 顧客,日付,商品,数量 A,20130406,a,1 A,20130408,b,1 A,20130416,c,1 B,20130407,k,2 C,20130408,d,1 C,20130409,e,4 $ mslide s=顧客,日付 k=顧客 f=商品:syo_ t=2 -n -assert_nullout i=dat1.csv o=rsl1.csv #WARNING# ; exist NULL in output data #END# kgslide -assert_nullout -n f=商品:syo_ i=dat1.csv k=顧客 o=rsl1.csv s=顧客,日付 t=2 $ more rsl1.csv 顧客,日付,商品,数量,syo_1,syo_2 A,20130406,a,1,b,c A,20130408,b,1,c, A,20130416,c,1,, B,20130407,k,2,, C,20130408,d,1,e, C,20130409,e,4,,
対応コマンド
mbest, mcat, mcombi, mcommon, mcount, mcsv2arff, mcut, mdelnull, mduprec, mfldname, mfsort, mnewnumber, mnewrand, mnewstr, mnrcommon, mnullto, mnumber, mproduct, mrand, msel, mselnum, mselrand, mselstr, msep, msep2, msetstr, msortf, mtee, mtonull, muniq, mvcount, mwindow, mxml2csv
上記のコマンドを除いてすべてのコマンドで利用できる。
2.9.15 precision= 有効桁数
内部的にはC言語におけるsprintfの書式「"%.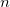 g"」を用いている。 この書式は、データの桁数と指定した有効桁数によって、標準標記(整数部.小数部: ex. 123.456)と、 指数表記(仮数部e
g"」を用いている。 この書式は、データの桁数と指定した有効桁数によって、標準標記(整数部.小数部: ex. 123.456)と、 指数表記(仮数部e 指数部: ex. 1.23456e+02)を切り替える。 切り替えの基準であるが、データを指数表記で表したときに、指数部が指定の有効桁数を超えるか、 もしくは-5以下の場合(すなわち、小数点以下に0が4つ以上続く場合)に指数表記を採用する。
指数部: ex. 1.23456e+02)を切り替える。 切り替えの基準であるが、データを指数表記で表したときに、指数部が指定の有効桁数を超えるか、 もしくは-5以下の場合(すなわち、小数点以下に0が4つ以上続く場合)に指数表記を採用する。
は1〜16の整数が指定可能で、デフォルトは10である。 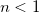 の場合は
の場合は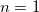 にセットされ、
にセットされ、 の場合は
の場合は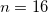 にセットされる。
にセットされる。
また、環境変数KG_Precisionを設定することでも有効桁数を変更できる。 ただし、環境変数を変更すると、それ以降に実行するコマンド全てに反映されることに注意する。
利用例
例1: 基本例
id=1は指数表現で1.2345678e+08であり、指数部が有効桁数6を超えているので指数表記となり、仮数部の有効桁数が6となっている。 id=2は指数表現で1.23456789e+03であり、指数部が有効桁数7を超えていないので標準標記となり、整数部+小数部の桁数が6となっている。 id=4は指数表現で1.23456789e-04であり、指数部が-4未満ではないので標準標記となり、有効桁数が6となっている。 id=5は指数表現で1.23456789e-05であり、指数部が-4未満となるため指数表記となり、仮数部の有効桁数が6となっている。
$ more dat1.csv
id,val
1,123456789
2,1234.56789
3,0.123456789
4,0.000123456789
5,0.0000123456789
$ mcal c='${val}' a=result precision=6 i=dat1.csv o=rsl1.csv
#END# kgcal a=result c=${val} i=dat1.csv o=rsl1.csv precision=6
$ more rsl1.csv
id,val,result
1,123456789,1.23457e+08
2,1234.56789,1234.57
3,0.123456789,0.123457
4,0.000123456789,0.000123457
5,0.0000123456789,1.23457e-05
例2: presicion=2の場合
$ mcal c='${val}' a=result precision=2 i=dat1.csv o=rsl2.csv
#END# kgcal a=result c=${val} i=dat1.csv o=rsl2.csv precision=2
$ more rsl2.csv
id,val,result
1,123456789,1.2e+08
2,1234.56789,1.2e+03
3,0.123456789,0.12
4,0.000123456789,0.00012
5,0.0000123456789,1.2e-05
例3: 環境変数による指定
環境変数によって設定すると、それ以降全てのコマンドがその設定値を使う。
$ export KG_Precision=4
$ mcal c='${val}' a=result i=dat1.csv o=rsl3.csv
#END# kgcal a=result c=${val} i=dat1.csv o=rsl3.csv
$ more rsl3.csv
id,val,result
1,123456789,1.235e+08
2,1234.56789,1235
3,0.123456789,0.1235
4,0.000123456789,0.0001235
5,0.0000123456789,1.235e-05
対応コマンド
msum, mcalなどの実数値の演算を伴うコマンド全てで利用できる。
2.9.16 tmpPath= 作業ファイル格納パス名
コマンドが内部で用いる作業ファイルを格納するディレクトリ名を指定する。 例えば、msortfは分割ソートにおいて並べ替えられた中間結果が一時ファイルとして保存される。 指定がなければデフォルトとして/tmpが用いられる。 一時ファイル名は、必ず__KGTMPから始まる。
作業ファイルは正常に終了すれば(エラー終了も含めてMCMDのコントロール下で正常に終了するという意味)削除されるが、 不測の事態、例えば停電やバグ終了の場合、消されず残る場合がある。 データ量によっては、非常に多くの作業ファイルが生成される可能性があり(100万ファイル以上!!)、 その場合は、コマンドの動作が極端に遅くなる可能性があるので、 定期的に作業パスのファイルを確認しておくべきである。 なお、現在のところ、これらの不要ファイルの自動消去(ガベージコレクション)の機能を実装する予定はない。
また、環境変数KG_Tmp_Pathを設定することで、作業ディレクトリを変更できる。 ただし、環境変数を変更すると、それ以降に実行するコマンド全てに反映されることに注意する。
利用例
例1: 基本例
カレントディレクトの直下のtmpディレクトリを作業ファイル用のディレクトリとする。
$ msortf f=val tmpPath=./tmp i=dat1.csv o=rsl1.csv #END# kgsortf f=val i=dat1.csv o=rsl1.csv tmpPath=./tmp
例2: 環境変数による指定
環境変数によって設定すると、それ以降全てのコマンドがその設定値を使う。
$ export KG_TmpPath=~/tmp $ msortf f=val i=dat1.csv o=rsl1.csv #END# kgsortf f=val i=dat1.csv o=rsl1.csv
対応コマンド
msortf, mdelnullなどのキー単位での選択を伴うコマンド、 mbucket mnjoin mshareなど、キー単位の処理において、データを複数パス走査する必要のあるコマンド。
2.9.17 delim= ベクトル要素の区切り文字
ベクトル型データについて、要素の区切り文字を指定する。 デフォルトは半角スペースである。 CSVの区切り文字であるカンマを指定することもできるが、 ベクトルの区切り文字と混同しないよう、ベクトル全体がダブルクオーテーションで囲われる。
利用例
例1: 基本例
コロンを区切り文字として、ベクトル項目vecの要素を並べ替える。
$ more dat1.csv vec b:a:c x:p $ mvsort vf=vec delim=: i=dat1.csv o=rsl1.csv #END# kgvsort delim=: i=dat1.csv o=rsl1.csv vf=vec $ more rsl1.csv vec a:b:c p:x
例2: delimを指定しないと
delimを指定していないのでb:a:cやx:pは一つの要素として解釈される。
$ mvsort vf=vec i=dat1.csv o=rsl2.csv #END# kgvsort i=dat1.csv o=rsl2.csv vf=vec $ more rsl2.csv vec b:a:c x:p
例3: カンマを区切り文字にする
区切り文字をカンマにした場合は、ベクトル全体がダブルクオーテーションで囲われることで CSVの区切り文字との区別がつけられる。
$ more dat2.csv id,vec1,vec2 1,a,b 2,p,q $ mvcat vf=vec1,vec2 a=vec3 delim=, i=dat2.csv o=rsl3.csv #END# kgvcat a=vec3 delim=, i=dat2.csv o=rsl3.csv vf=vec1,vec2 $ more rsl3.csv id,vec3 1,"a,b" 2,"p,q"
対応コマンド
mvcat, mvsortなどベクトル型項目を扱うコマンド全てに適用できる。
2.9.18 bufcount= バッファの数
mbucket,mnjoin,mshareなど、キー単位の処理において、データを複数パス走査する必要のあるコマンドにおいて 利用する内部バッファの数(ブロック数)を指定する。 一つのバッファは4MBで、デフォルトでは10ブロック(40MB)である。 データがバッファに収まらない場合は一時ファイルに書き出されるため、 キーのサイズが非常に大きい場合は、メモリに余裕があれば、このパラメータを調整することで処理速度の向上が期待できる。
利用例
例1: 基本例
参照ファイルのキーサイズが80MB(4MB×20)以内であれば、一時ファイルは使われない。
$ mnjoin k=id m=ref.csv f=name i=dat.csv o=rsl.csv bufcount=20 #END# kgnjoin bufcount=20 f=name i=dat.csv k=id m=ref.csv o=rsl.csv
対応コマンド
mbucket, mnjoin, mshareなど、キー単位の処理において、データを複数パス走査する必要のあるコマンド。
| MCMD2 |