| MCMD2 |
3.62 msummary 1変数の統計量の計算
f=パラメータで指定した集計項目で c=パラメータで指定した統計量の計算をする。
書式
msummary c= f= [a=] [k=] [-n] [i=] [o=] [-assert_diffSize] [-assert_nullkey] [-assert_nullin] [-assert_nullout] [-nfn] [-nfno] [-x] [-q] [tmpPath=] [precision=] [--help] [--helpl] [--version]
パラメータ
k= |
キー項目名リスト(複数項目指定可)【集計キーブレイク処理】 |
ここで指定された項目を単位として集計する。 |
|
指定する場合は事前に指定する集計の単位となる項目順に並べ替えておく必要がある。 |
|
f= |
集計項目名リスト(複数項目指定可) |
ここで指定された項目の値が集計される。 |
|
-x,-nfnオプション使用時は、項目番号(0~)で指定。 |
|
c= |
統計量リスト(複数項目指定可) |
出力する統計量をコンマで区切って指定する。 |
|
統計量リスト: |
|
sum/mean/count/ucount/devsq/var/uvar/sd/usd/cv/min/qtile1/median/qtile3/max/ |
|
range/qrange/mode/skew/uskew/kurt/ukurt |
|
-a |
新項目名 |
f=パラメータで指定した項目名をデータとして出力する際の項目名(省略時はfld)を指定する。 |
統計量リスト
c=パラメータで指定できる統計量と定義をTable 3.32に示す。
c=の値 |
内容 |
式 |
備考 |
count |
件数(NULL値以外) |
|
文字列項目に対しては適用できない。 |
ucount |
ユニーク件数 |
|
文字列項目に対しては適用できない。 |
sum |
合計 |
|
|
mean |
算術平均 |
|
|
devsq |
偏差平方和 |
|
|
var |
分散 |
|
|
uvar |
分散(不偏推定値) |
|
|
sd |
標準偏差 |
|
|
usd |
標準偏差(不偏分散のsqrt) |
|
一般的によく使われる標準偏差 |
cv |
変動係数 |
|
|
mode |
最頻値 |
|
全ての値が異なる場合はNULLを、同頻度 |
の場合はより小さい方の値を出力する。 |
|||
min |
最小値 |
|
|
max |
最大値 |
|
|
range |
範囲 |
|
|
median |
中央値 |
|
|
qtile1 |
第1四分位点 |
|
|
qtile3 |
第1四分位点 |
|
|
qrange |
四分位範囲 |
|
|
skew |
歪度 |
|
|
uskew |
歪度(不偏推定値) |
省略 |
|
kurt |
尖度 |
|
|
ukurt |
尖度(不偏推定値) |
省略 |
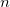 : NULL値以外の件数
: NULL値以外の件数 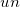 : 重複値を省いた件数
: 重複値を省いた件数 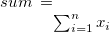
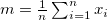
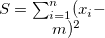
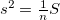
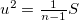
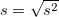
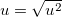
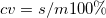
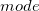 : 最頻出の値
: 最頻出の値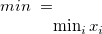
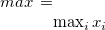
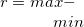
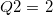
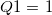
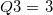
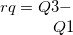
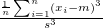
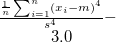
利用例
例1: 基本例
「顧客」項目を単位に「数量」と「金額」項目の中央値・平均値を求める。 統計量を求めた項目名は「変数」という項目に出力する。
$ more dat1.csv 顧客,数量,金額 A,1,10 A,2,20 B,1,15 B,3,10 B,1,20 $ msummary k=顧客 f=数量,金額 c=median:中央値,mean:平均値 a=変数 i=dat1.csv o=rsl1.csv #END# kgsummary a=変数 c=median:中央値,mean:平均値 f=数量,金額 i=dat1.csv k=顧客 o=rsl1.csv $ more rsl1.csv 顧客%0,変数,中央値,平均値 A,数量,1.5,1.5 A,金額,15,15 B,数量,1,1.666666667 B,金額,15,15
関連コマンド
mstats : 求める統計量が1つのとき用いる。
| MCMD2 |