| MCMD2 |
3.60 mstats 一変数の統計量算出
f=パラメータで指定した数値項目について c=パラメータで指定した統計量の計算をする。 k=を指定することで、キー単位で集計することができる。 f=で指定した項目のNULL値は無視される。 ただし、全行がNULL値であればNULL値が出力される。 (注)k=とf=パラメータで指定した項目以外については、どの行が出力されるか>は不定であることに注意してください。
書式
mstats c= f= [k=] [-n] [i=] [o=] [-assert_diffSize] [-assert_nullkey] [-assert_nullin] [-assert_nullout] [-nfn] [-nfno] [-x] [-q] [tmpPath=] [precision=] [--help] [--helpl] [--version]
パラメータ
k= |
ここで指定された項目(複数項目指定可)を単位として集計する。 |
f= |
ここで指定された項目(複数項目指定可)の値が集計される。 |
c= |
統計量(以下のリストから一つだけ指定可) |
sum|mean|count|ucount|devsq|var|uvar|sd|usd|USD|cv|min|qtile1| |
|
median|qtile3|max|range|qrange|mode|skew|uskew|kurt|ukurt |
統計量リスト
c=の値 |
内容 |
式 |
備考 |
count |
件数(NULL値以外) |
|
文字列項目に対しては適用できない。 |
ucount |
ユニーク件数 |
|
文字列項目に対しては適用できない。 |
sum |
合計 |
|
|
mean |
算術平均 |
|
|
devsq |
偏差平方和 |
|
|
var |
分散 |
|
|
uvar |
分散(不偏推定値) |
|
|
sd |
標準偏差 |
|
|
usd |
標準偏差(不偏分散のsqrt) |
|
一般的によく使われる標準偏差 |
USD |
不偏標準偏差 |
省略 |
正確な不偏推定 |
cv |
変動係数 |
|
|
mode |
最頻値 |
|
全ての値が異なる場合はNULLを、同頻度 |
の場合はより小さい方の値を出力する。 |
|||
min |
最小値 |
|
|
max |
最大値 |
|
|
range |
範囲 |
|
|
median |
中央値 |
|
|
qtile1 |
第1四分位点 |
|
|
qtile3 |
第1四分位点 |
|
|
qrange |
四分位範囲 |
|
|
skew |
歪度 |
|
|
uskew |
歪度(不偏推定値) |
省略 |
|
kurt |
尖度 |
|
|
ukurt |
尖度(不偏推定値) |
省略 |
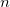 : NULL値以外の件数
: NULL値以外の件数 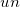 : 重複値を省いた件数
: 重複値を省いた件数 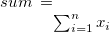
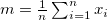
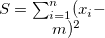
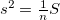
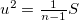
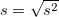
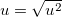
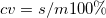
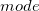 : 最頻出の値
: 最頻出の値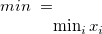
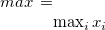
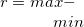
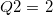
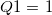
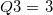
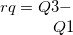
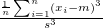
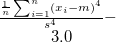
利用例
例1: 基本例
「顧客」項目を単位に「数量」と「金額」項目の 各統計量合計値を計算する。
$ more dat1.csv 顧客,数量,金額 A,1,10 B,5,20 B,2,10 C,1,15 C,3,10 C,1,21 $ mstats k=顧客 f=数量,金額 c=sum i=dat1.csv o=rsl1.csv #END# kgstats c=sum f=数量,金額 i=dat1.csv k=顧客 o=rsl1.csv $ more rsl1.csv 顧客%0,数量,金額 A,1,10 B,7,30 C,5,46
例2: 基本例2
各統計量最大値を計算する。
$ mstats k=顧客 f=数量,金額 c=max i=dat1.csv o=rsl2.csv #END# kgstats c=max f=数量,金額 i=dat1.csv k=顧客 o=rsl2.csv $ more rsl2.csv 顧客%0,数量,金額 A,1,10 B,5,20 C,3,21
関連コマンド
msim : 2変量の統計量を求める。
mavg : c=avgに特化したコマンド。
msum : c=sumに特化したコマンド。
mcount : c=countと異なり、集計キーの行数をカウントする。
| MCMD2 |