| MCMD2 |
3.44 mrand 擬似乱数
0.0から1.0の範囲の実数の擬似乱数、もしくは範囲指定による整数の擬似乱数を生成し、a=パラメータで指定した項目名で出力する。
乱数の生成にはメルセンヌ・ツイスター法を利用している (原作者のページ , boostライブラリ)。
書式
mrand [k=] a= [max=] [min=] [S=] [-int] [i=] [o=] [-assert_diffSize] [-assert_nullkey] [-nfn] [-nfno] [-x] [-q] [tmpPath=] [--help] [--helpl] [--version]
パラメータ
k= |
指定したキー項目について、同じキー値には同じ乱数値が振られる。 |
a= |
新たに追加される項目の名前を指定する。【但し、-nfn,-nfnoオプション指定時は必要なし】 |
max= |
乱数の最大値【デフォルト値:INT_MAX】 |
0〜 |
|
このパラメータを指定するときは-intも指定しなければならない。 |
|
min= |
整数乱数の最小値【デフォルト値:0】 |
0〜 |
|
このパラメータを指定するときは-intも指定しなければならない。 |
|
S= |
乱数の種【デフォルト値:現在時刻】 |
同じ乱数の種を指定すれば、同じ乱数系列となる。 |
|
S=を指定しなければ、時刻(ミリ(1/1000秒単位)に応じた異なる乱数の種が利用される。 |
|
指定可能な乱数の種(-2147483648〜2147483647) |
|
-int |
整数乱数を生成 |
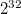 (約21億)の範囲の整数が指定可能
(約21億)の範囲の整数が指定可能利用例
例1: 基本例
0.0から1.0の範囲の実数乱数を生成する。
$ more dat1.csv 顧客 A B C D E $ mrand a=rand i=dat1.csv o=rsl1.csv #END# kgrand a=rand i=dat1.csv o=rsl1.csv $ more rsl1.csv 顧客,rand A,0.6167292702 B,0.6462748032 C,0.8155993843 D,0.3809444529 E,0.8053956977
例2: 基本例2
-intで整数乱数
$ mrand a=rand -int i=dat1.csv o=rsl2.csv #END# kgrand -int a=rand i=dat1.csv o=rsl2.csv $ more rsl2.csv 顧客,rand A,1307854271 B,888117524 C,752405937 D,1761916556 E,1235161444
例3: 最小値、最大値を決めた乱数の生成
最小値が10、最大値が100の整数の乱数を生成し、randという項目名で出力する。
$ mrand a=rand -int min=10 max=100 S=1 i=dat1.csv o=rsl3.csv #END# kgrand -int S=1 a=rand i=dat1.csv max=100 min=10 o=rsl3.csv $ more rsl3.csv 顧客,rand A,47 B,100 C,75 D,94 E,10
例4: キー単位の乱数生成
以下の例は、顧客A,B,C,Dの4人について同じ顧客には同じ乱数値を振る。
$ more dat2.csv 顧客 A A A B B C D D D $ mrand k=顧客 -int min=0 max=1 a=rand i=dat2.csv o=rsl4.csv #END# kgrand -int a=rand i=dat2.csv k=顧客 max=1 min=0 o=rsl4.csv $ more rsl4.csv 顧客%0,rand A,0 A,0 A,0 B,1 B,1 C,0 D,0 D,0 D,0
関連コマンド
mselrand : ランダムに行を選択する。
mnewrand : 入力ファイルなしに、乱数データを新たに生成する。
| MCMD2 |